Embedding Real-Time Machine Learning Pipelines inside Java Microservices
Introduction
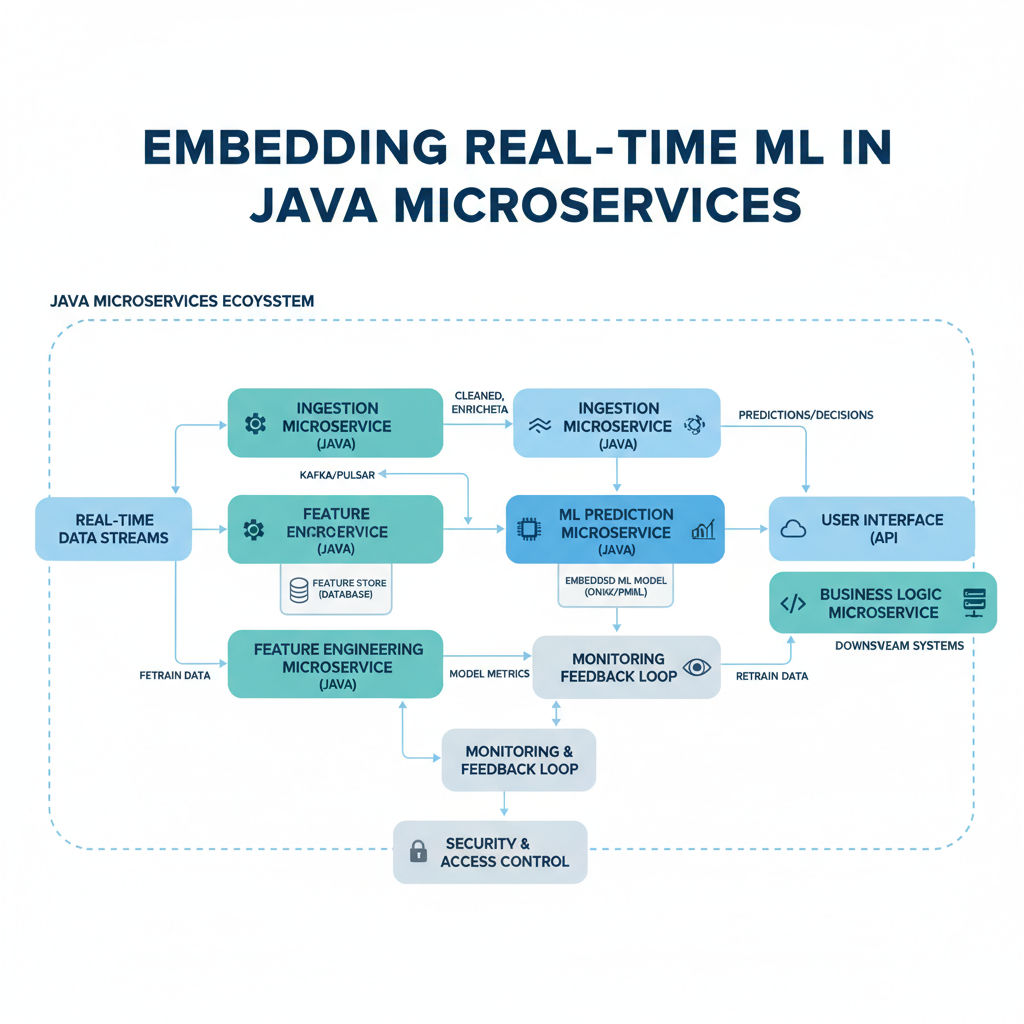
You’re about to learn how to build a system that can predict fraud, recommend products, or detect anomalies within milliseconds of new data arriving — all running inside a Java microservice. This isn’t about batch processing where you train models overnight and hope for the best. It’s about real-time decisions, streaming data, and pipelines that never stop.
Here’s what we’ll demystify: Pipelines (the chain of processing steps), Microservices (small, independent applications), Streaming (data that flows continuously), Real-time (decisions made instantly), and Kafka (the messaging backbone that makes it all work). By the end, you’ll understand how these pieces fit together to create ML systems that react to the world as it happens.
Pipelines: The Assembly Line for Data
Plain-English definition: A pipeline is a sequence of processing steps where data enters one end and results come out the other. Each step transforms the data a little bit.
How it works: Think of a car factory. Chassis goes in, wheels get added, then the engine, then paint. Each station does one job. A machine learning pipeline works similarly: raw data goes in, features get extracted, then the model makes a prediction, then that prediction gets formatted for output. Each step is independent, so you can swap out the model without touching the feature extraction code.
Analogies: Imagine making coffee. You grind beans (step 1), heat water (step 2), brew (step 3), pour (step 4). Change the grind, and the rest adapts. Same idea with ML pipelines — change the model, and the preprocessing and postprocessing stay the same.
Code example:
// A simple ML pipeline using Apache Beam (runs both streaming and batch)
Pipeline pipeline = Pipeline.create(options);
pipeline
.apply("Read from Kafka", KafkaIO.read().withBootstrapServers("localhost:9092"))
.apply("Parse JSON", ParDo.of(new JsonParser()))
.apply("Extract Features", ParDo.of(new FeatureExtractor()))
.apply("Predict", ParDo.of(new FraudDetectionModel()))
.apply("Write Results", KafkaIO.write().withTopic("predictions"));
pipeline.run();
That’s it. Five steps chained together. Each .apply() is a station on the assembly line.
Microservices: Small, Focused, Independent
Plain-English definition: A microservice is a tiny application that does one thing well and communicates with other services over a network. It’s the opposite of a giant monolithic application where everything is tangled together.
How it works: Instead of one big program that handles user accounts, payments, and ML predictions, you have separate services. The ML microservice only runs models. When another service needs a prediction, it sends a request via HTTP or message queue. This means you can scale the ML service independently — if predictions are in high demand, you run more copies of just that service.
Analogy: Think of a restaurant kitchen. Instead of one chef doing everything, you have a salad station, a grill station, and a dessert station. Each station is a microservice. Orders flow between them. If salads become popular, you can add more salad stations without changing the grill.
Real example with Spring Boot:
@RestController
public class PredictionController {
@Autowired
private ModelService modelService;
@PostMapping("/predict")
public PredictionResponse predict(@RequestBody Features features) {
// Microservice receives request, runs model, returns result
double score = modelService.evaluate(features);
return new PredictionResponse(score > 0.8, score);
}
}
This microservice doesn’t know anything about authentication, payments, or user profiles. It just predicts.
Streaming: Data That Never Stops Flowing
Plain-English definition: Streaming means processing data as it arrives, continuously, rather than waiting for a complete batch. Think of a river vs. a lake.
How it works: Traditional batch processing waits for all data to be collected, then processes it once. Streaming processes each record as it arrives. For fraud detection, you can’t wait 24 hours for all transactions to arrive before checking for fraud. You need to check each one the instant it happens.
Analogy: Imagine a conveyor belt carrying apples. A batch system would let the belt fill a bin, then inspect the whole bin at once. A streaming system inspects every single apple as it passes.
Code example using Kafka Streams:
KStream<String, Transaction> transactions = builder.stream("transactions");
KStream<String, Alert> alerts = transactions
.filter((key, tx) -> tx.getAmount() > 10000) // Check amount
.mapValues(tx -> {
// Run ML model on the streaming transaction
double fraudScore = model.predict(tx);
return new Alert(tx, fraudScore);
});
alerts.to("fraud-alerts"); // Output results to another topic
Notice how there’s no loop, no waiting. Data flows through continuously. The model runs on every single transaction in real time.
Real-Time: Decisions in Milliseconds
Plain-English definition: Real-time means the system responds within a bounded, predictable time — usually milliseconds. It’s not “fast” — it’s “fast enough that the user never notices a delay.”
How it works: Real-time systems prioritize latency over throughput. They trade batch efficiency for immediate responsiveness. In ML context, the model must load, preprocess input, and produce a prediction within, say, 50 milliseconds for credit card authorization.
Analogy: A real-time system is like a goalkeeper diving for a penalty kick. There’s no time to analyze a season’s worth of kicks. The decision has to happen in a fraction of a second based on what’s happening right now.
Gotcha: Model loading time kills real-time performance. Loading a large neural network from disk can take seconds. Solution: Pre-load models at startup, or use model serving frameworks like TensorFlow Serving.
@Component
public class FraudDetectionService {
private final Model model;
public FraudDetectionService() {
// Load model once at startup, not per request
this.model = Models.load("/models/fraud-detection.zip");
}
public double predict(Transaction transaction) {
long start = System.currentTimeMillis();
double score = model.evaluate(transaction);
long elapsed = System.currentTimeMillis() - start;
if (elapsed > 50) {
log.warn("Prediction took {}ms, goal is < 50ms", elapsed);
}
return score;
}
}
Kafka: The Nervous System That Connects Everything
Plain-English definition: Kafka is a distributed message broker — it’s like a post office for microservices. Services send messages to named “topics” (like mailboxes), and other services read from those topics when they’re ready.
How it works: Producers send messages to topics. Consumers subscribe to topics and process messages. Multiple consumers can read the same topic without interfering because Kafka tracks which messages each consumer has read. This allows your ML microservice to consume transactions, process them, and output predictions — all without blocking the original transaction service.
Analogy: Kafka is like a very organized bulletin board. Anyone can post a note (produce), and anyone can read posted notes (consume). Multiple people can read the same note simultaneously. Notes don’t disappear after being read — they stay for others to see later.
Code example:
// Producer sends transactions to Kafka
public class TransactionProducer {
public void sendTransaction(Transaction tx) {
ProducerRecord<String, Transaction> record =
new ProducerRecord<>("transactions", tx.getUserId(), tx);
producer.send(record, (metadata, exception) -> {
if (exception != null) {
log.error("Failed to send transaction", exception);
}
});
}
}
// Consumer reads transactions and sends results back
public class FraudConsumer {
@KafkaListener(topics = "transactions")
public void consume(ConsumerRecord<String, Transaction> record) {
Transaction tx = record.value();
double score = fraudService.predict(tx);
// Send result to a different topic
kafkaTemplate.send("fraud-results",
new FraudResult(tx.getTransactionId(), score > 0.8));
}
}
How It All Fits Together
Here’s a comparison table that shows how each concept plays a specific role in the system:
| Concept | Role | Analogy | Key Gotcha |
|---|---|---|---|
| Pipeline | Processing structure | Assembly line | Hard to debug, need monitoring |
| Microservice | Deployment unit | Restaurant station | Network latency between services |
| Streaming | Data arrival pattern | Conveyor belt | State management is complex |
| Real-time | Time constraint | Goalkeeper | Model loading time ruins latency |
| Kafka | Communication backbone | Bulletin board | Setting the right number of partitions |
Numbered flow of a request:
- User initiates a transaction → sent to Kafka topic “transactions”
- Fraud detection microservice (consumer) reads from “transactions”
- Pipeline processes the transaction: parse → extract features → predict → format result
- Result sent to Kafka topic “fraud-results” within 50 milliseconds
- Authorization microservice reads “fraud-results” and approves or declines
Key Takeaways
- Pipelines make ML processing modular and testable — swap components without rebuilding
- Microservices keep each piece focused and independently scalable
- Streaming handles data as it arrives, not after collecting everything
- Real-time means bounded latency, not just speed (monitor your model load times!)
- Kafka decouples producers from consumers, enabling asynchronous, resilient communication
- Combine them all for a system that reacts to events in milliseconds while remaining maintainable

Comments