Architecting a Resilient Java API Gateway for ML Model Serving
Imagine you’re responsible for serving machine learning predictions to thousands of users per second. Your ML models are powerful, but they’re also finicky. One model might take 500ms to respond, another might crash entirely. Without a resilient gateway, a single slow model could cascade into a full system outage.
In this tutorial, you’ll learn exactly how to build a Java API gateway that handles these challenges gracefully. We’ll demystify five critical concepts: resilience, gateway architecture, latency management, fallback strategies, and performance optimization. By the end, you’ll have a working gateway that keeps serving predictions even when your models misbehave.
Resilience: Why Your Gateway Shouldn’t Die Like a Single Fish in a Net
Resilience means your system keeps working even when parts of it fail. Think of it like a fishing net with multiple compartments. If one compartment tears, the fish in other compartments stay safe. The net as a whole still catches fish.
Under the hood, resilience in a Java gateway works through isolation patterns. Instead of making direct calls to ML models, you wrap each call in a protective circuit breaker. This circuit breaker monitors for failures. When too many requests fail, the circuit “opens” and stops failing requests from reaching the already-broken model.
// Resilience4j CircuitBreaker configuration
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // Open circuit if 50% of requests fail
.waitDurationInOpenState(Duration.ofSeconds(30)) // Wait 30s before retrying
.slidingWindowSize(10) // Check last 10 requests
.build();
CircuitBreaker modelBreaker = CircuitBreaker.of("prediction-api", config);
// Decorate your ML model call
Supplier<Prediction> decorated = CircuitBreaker.decorateSupplier(
modelBreaker,
() -> mlClient.predict(inputData)
);
The non-obvious insight here is that circuit breakers don’t just protect downstream services — they protect your gateway’s resources from being consumed by failing requests. Every thread waiting on a timeout is a thread not handling successful requests.
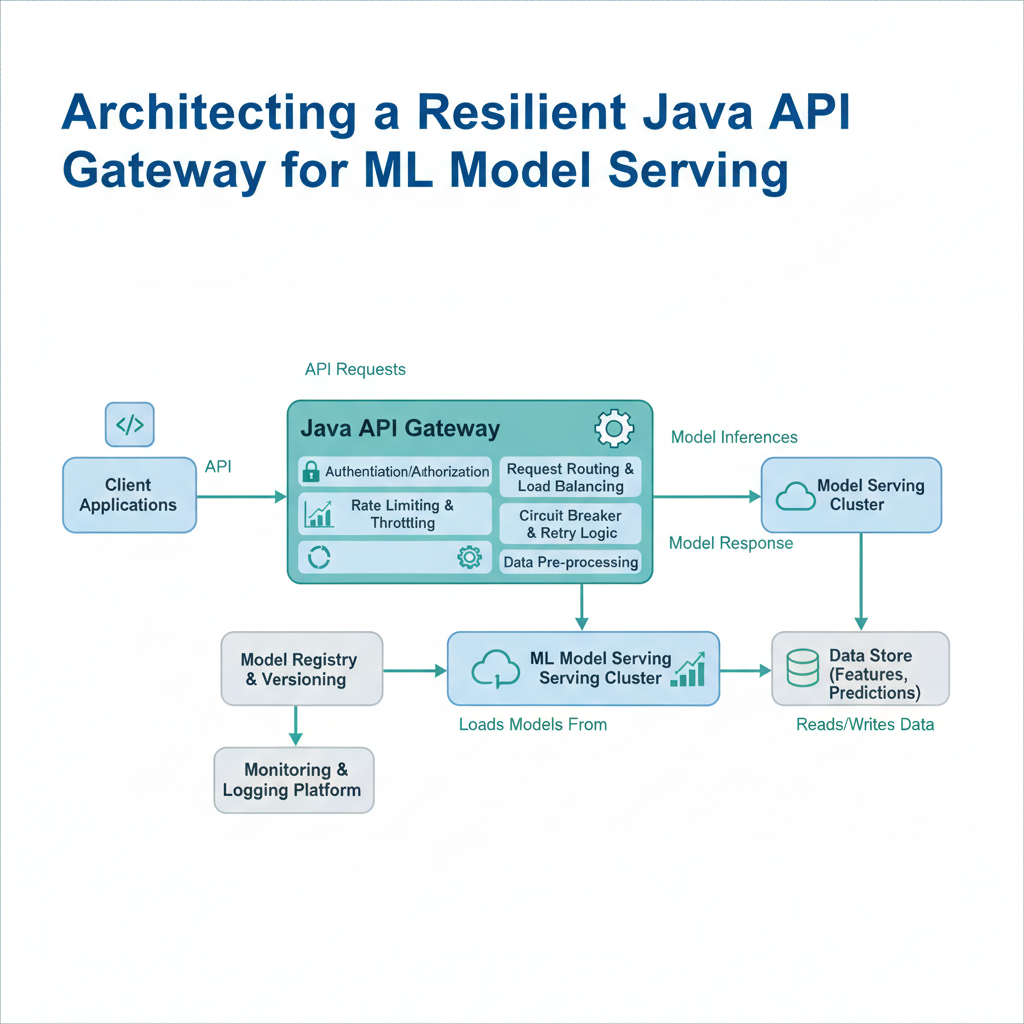
Gateway: Your API’s Bouncer and Traffic Cop
A gateway is a single entry point that sits between your clients and your backend services. Think of it like a nightclub bouncer: the bouncer checks IDs, directs people to the right room, and kicks out troublemakers before they cause problems.
Under the hood, a Java gateway like Spring Cloud Gateway routes incoming HTTP requests to the appropriate ML model service. But it does more than just routing — it handles authentication, rate limiting, request transformation, and response aggregation.
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("ml-model-1", r -> r
.path("/predict/v1/**")
.filters(f -> f
.circuitBreaker(config -> config
.setName("model1CB")
.setFallbackUri("forward:/fallback/predict")))
.uri("http://model1-service:8081"))
.route("ml-model-2", r -> r
.path("/predict/v2/**")
.uri("http://model2-service:8082"))
.build();
}
The gotcha most tutorials skip: gateways are themselves a single point of failure. Deploy at least two instances behind a load balancer, or your “resilient” gateway becomes your system’s weakest link.
Latency: The Hidden Cost of Every Model Call
Latency is the time between sending a request and receiving a response. For ML model serving, it’s the time from “predict this” to “here’s your prediction.” Think of it like ordering coffee — the latency includes the barista taking your order, making the coffee, and handing it to you.
Under the hood, latency consists of network travel time, request processing, and model inference time. A single ML model call might involve feature engineering, model inference, and response post-processing — each adding milliseconds.
// Measure and log latency at each stage
long startTime = System.nanoTime();
// Stage 1: Feature extraction
FeatureVector features = featureStore.get(inputData);
long featureTime = System.nanoTime();
logger.info("Feature extraction took: {} ms",
TimeUnit.NANOSECONDS.toMillis(featureTime - startTime));
// Stage 2: Model inference
Prediction prediction = mlModel.predict(features);
long inferenceTime = System.nanoTime();
logger.info("Model inference took: {} ms",
TimeUnit.NANOSECONDS.toMillis(inferenceTime - featureTime));
Here’s the counterintuitive truth: reducing latency isn’t always about making individual operations faster. Often, the biggest gains come from reducing contention — fewer concurrent requests waiting on the same thread pool. Adding more threads can paradoxically increase latency due to context switching overhead.
Fallback: Your System’s Safety Net
A fallback is a default response or alternative action when the primary service fails. Think of it like a backup parachute — you hope you never need it, but you’re glad it’s there when the main one fails.
Under the hood, fallbacks in a Java gateway are triggered by circuit breakers or timeouts. When a model service is unavailable, the gateway returns a cached prediction, a simplified model result, or a graceful error message instead of crashing.
@Component
public class PredictionFallback implements FallbackHandler {
private final Cache<String, Prediction> predictionCache;
@Override
public Mono<Void> handle(ServerWebExchange exchange, Throwable t) {
String modelKey = extractModelKey(exchange.getRequest());
// Fallback to cached prediction
Prediction cached = predictionCache.getIfPresent(modelKey);
if (cached != null) {
return respondWith(exchange, cached, HttpStatus.OK);
}
// Ultimate fallback: graceful error
return respondWith(exchange,
new Prediction("Model unavailable, try again later"),
HttpStatus.SERVICE_UNAVAILABLE);
}
}
The edge case that catches everyone: fallbacks can mask real problems. If your circuit breaker opens and the fallback always returns “success,” you’ll never know your model is down. Always log which path was taken (primary vs. fallback) separately.
Performance: Doing More with Less
Performance in an ML gateway means handling maximum requests with minimum resources. It’s not just about speed — it’s about efficiency. Think of it like a restaurant kitchen: performance isn’t just cooking faster, it’s using your stoves, chefs, and ingredients optimally.
Under the hood, performance involves thread pool sizing, connection pooling, request batching, and caching. A well-tuned gateway can handle 10x the load of an unoptimized one with the same hardware.
// Thread pool configuration for ML model calls
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // Minimum threads
executor.setMaxPoolSize(25); // Maximum threads
executor.setQueueCapacity(100); // Backlog queue
executor.setThreadNamePrefix("ml-worker-");
// Connection pooling for HTTP calls to model services
PoolingHttpClientConnectionManager connectionManager =
PoolingHttpClientConnectionManagerBuilder.create()
.setMaxTotal(50) // Total connections
.setDefaultMaxPerRoute(20) // Per model endpoint
.build();
The performance gotcha: bigger thread pools aren’t always better. With model inference calls that take hundreds of milliseconds, too many threads means thread contention and garbage collection pressure. Profile with realistic load before tuning.
When to Use Each Pattern
Here’s how these concepts work together when architecting your gateway:
| Concept | Primary Purpose | When to Use | Key Trade-off |
|---|---|---|---|
| Resilience | System survival | Always, but especially with unreliable models | Adds complexity, slight overhead |
| Gateway | Request routing & management | Multiple model services | Single point of failure |
| Latency | Response speed | User-facing APIs | Trade accuracy for speed if needed |
| Fallback | Graceful degradation | Critical systems | Masks errors if not logged |
| Performance | Resource efficiency | At scale | Over-optimization wastes dev time |
Key Takeaways
- Resilience uses circuit breakers and isolation to keep your gateway alive when models fail
- Gateway patterns route requests, handle auth, and add cross-cutting concerns
- Latency must be measured at each stage, and reducing contention often beats speeding up individual operations
- Fallback strategies provide grace but require careful monitoring to avoid masking failures
- Performance tuning is about efficiency under load, not just raw speed
Each concept buys you something different. Resilience keeps you alive. Fallbacks keep users happy. Performance keeps costs down. Use them together, and your ML serving pipeline becomes something you can actually sleep through the night knowing it works.

Comments