Your Microservices Mesh Is Secretly a Distributed Monolith
You optimized every service. You broke the monolith into 47 microservices, added a service mesh, and watched performance magically improve. Except it didn’t. Your p99 latency is actually worse than the monolith you replaced. The metrics dashboard shows red alerts across your cluster, and SREs are paged at 3 AM for cascading failures that look suspiciously like… a monolith. The industry’s biggest lie is that microservices solve complexity. They don’t. They just relocate it—from your codebase to your network, where it’s harder to measure, harder to fix, and much more expensive.
The Temperature Check Myth
We’ve normalized something bizarre: spinning up 50 Node.js services and calling it “evolution.” Basecamp famously ran their entire business on a single Rails app for over a decade. When they finally split, they ended up maintaining more code in their integration layer than any single service contained.
The surface-level assumption is that microservices simplify development. Teams own their code, deploy independently, and scale vertically. But here’s the juxtaposition: every major platform that publicly evangelizes microservices (Netflix, Uber, DoorDash) has privately admitted they’re dealing with “distributed monoliths”—services that are technically separate but logically inseparable.
That service mesh you’re running? It’s not solving the problem. It’s adding 3-5 milliseconds of latency per hop, per request. Uber’s internal benchmarks showed their service mesh added 12-20ms to their p99 latency before any business logic ran.
Let that sink in: your infrastructure is making your application slower.
The Real Cost of Abstractions
Every service abstraction has a transfer cost. Every time your service calls another, there’s serialization, deserialization, network I/O, protocol overhead, authentication checks, and mesh routing. The technical term is serialization tax, but I prefer “the distributed overhead principal.”
Here’s the mechanism: when your monolith calls a function, it’s a CPU instruction. When your microservice calls another service, it’s a network round trip. The difference is the difference between a nanosecond and a millisecond—a factor of 1,000,000x.
“Your service mesh isn’t making things faster. It’s making things more expensive.”
— Anonymous Netflix SRE interview
Imagine sending a letter across town to ask your colleague for the contents of a variable. That’s microservices. The monolith just turned around in their chair and asked. Same information, radically different cost.
Now compound this across a typical 15-service user request chain. Each service adds its own overhead. The total cost isn’t additive—it’s multiplicative, because services retry, timeouts cascade, and circuit breakers trip.
Netflix reported that 40% of their request latency came from service mesh overhead alone. Not business logic. Infrastructure.
The Blind Spot Nobody Talks About
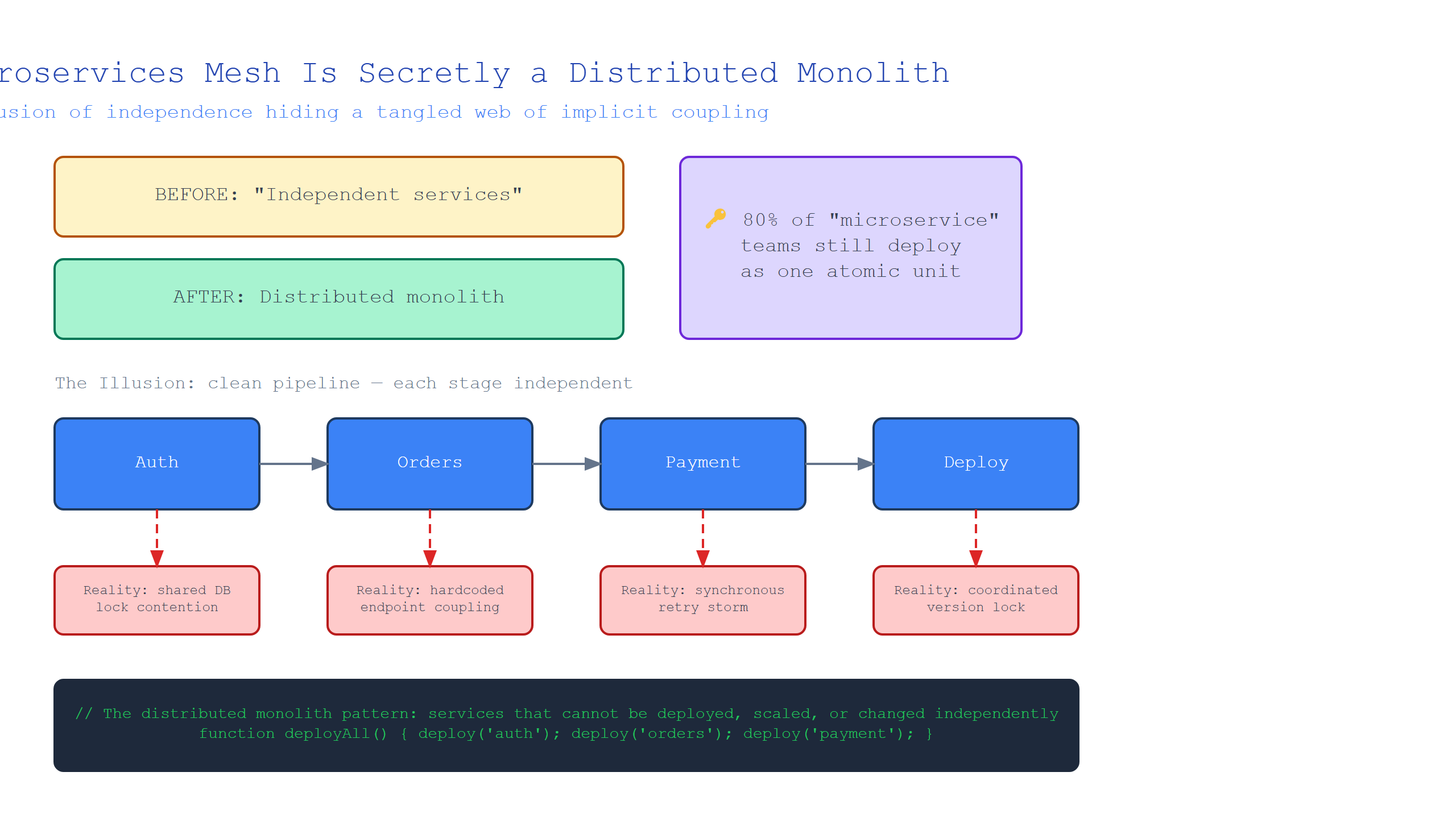
Everyone’s missing the same thing: logical coupling. Your services might be physically separate, but they share schemas, error handling logic, authentication tokens, and deployment dependencies.
When service A expects service B to return a specific JSON structure, and service B changes it, your distributed monolith breaks. That’s not independence. That’s coupling with extra steps.
The blind spot is that teams measure the wrong things. They look at deployments per week (independent!), while ignoring that every deployment requires coordinated schema updates across 4 teams and a week of integration testing.
Dave Farley, co-author of “Continuous Delivery,” calls this distributed coherence—a fancy term for “you just built a monolith that requires network calls instead of function calls.”
Here’s the counter-intuitive truth: the most successful microservices architectures I’ve seen use very few microservices. Shopify runs on 7. Doordash trimmed from 200 to 30. They realized that every service boundary adds cognitive load proportional to the number of teams maintaining it.
Three red flags you’re running a distributed monolith:
- Your deploy requires coordinated schema changes across services
- A service boundary feels more like a polite fiction than a true API
- You spend more time debugging the service mesh than writing business logic
The Performance Apocalypse
Forward-looking implications are stark: as infrastructure abstraction layers multiply (service meshes, sidecars, function-as-a-service), the serialization tax grows.
Amazon’s internal analysis showed that their Lambda invocations for a single transaction spent 60% of their execution time on infrastructure overhead—cold starts, VPC networking, IAM credential resolution, and CloudWatch logging.
Compare that to a well-tuned monolith on a single EC2 instance: 10% overhead.
The industry’s reflex is to throw money at the problem. More instances, bigger instances, memory-optimized instances. But you can’t buy your way out of physics. Every microservice boundary is a physical limit: the speed of light, the bus width, the TCP window size.
What this means: your cloud bill is going to grow linearly with your service count. Your latency will grow exponentially. And your customer experience will degrade proportionally.
Smart teams are rediscovering modular monoliths—separating logical modules while keeping a single deployment unit. At least those don’t require a Kubernetes cluster to run a CRUD API.
- Microservices don’t eliminate complexity; they relocate it from code to network
- Your service mesh adds 3-5ms per hop, making your system slower
- Logical coupling means you’ve built a distributed monolith
- Physical overhead (serialization, cold starts) is 40-60% of runtime in practice
- Fewer, larger services beat many small ones for latency
The Only Way Forward
Stop abstracting blindly. Measure what really matters: end-to-end latency, not deployments per week. Consider the modular monolith before jumping to microservices. And if you absolutely must split, keep your services functionally independent, not just physically separate.
The best architecture is the one that lets you respond to a customer bug at 3 AM without tracing through 4 Zipkin spans waiting for a timeout.
That’s not a microservice. That’s a monolith with PTSD.

Comments