Agent Infrastructure Is Becoming More Important Than Models
Published: April 15, 2025
Imagine you’ve built the world’s most brilliant chef. They know every recipe, every technique, every ingredient. But they’re locked in a pantry with no stove, no pots, and no way to get groceries. That’s our AI industry right now.
We’ve been obsessed with building smarter models. Bigger neural networks, more parameters, better reasoning. And sure, models are getting impressively smart. But here’s the uncomfortable truth: a mediocre model with great infrastructure will outperform a brilliant model with none.
In this post, you’ll learn exactly what agent infrastructure means, why it’s suddenly the bottleneck, and how to think about building systems that let AI agents actually do useful work. We’ll cover:
- Agent infrastructure vs. models
- Memory systems and state management
- Tool integration and API orchestration
- Error handling and recovery patterns
- Observability and debugging in agent systems
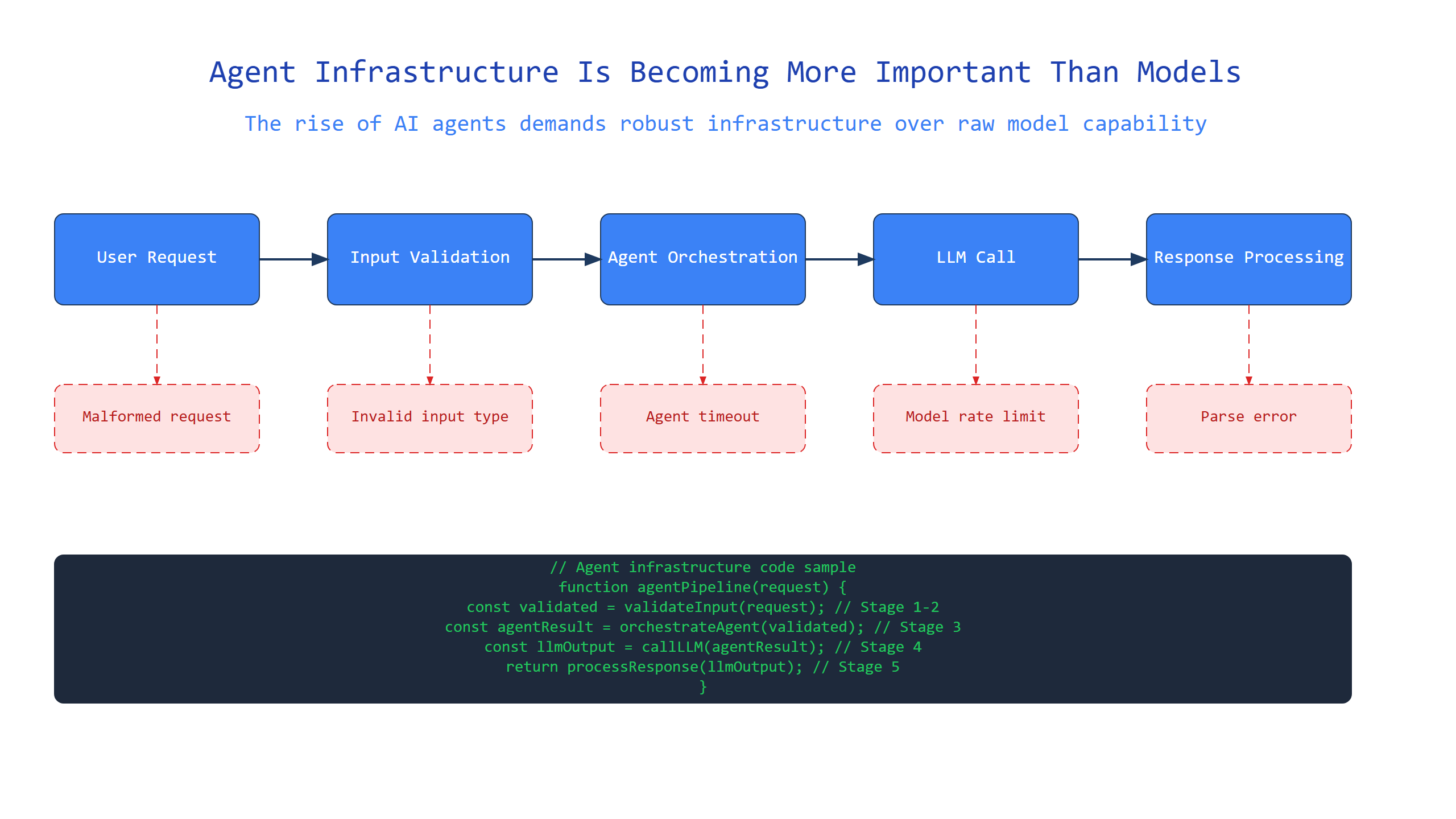
The Infrastructure Blind Spot
Here’s a surprising juxtaposition: we spend millions training models that can pass the bar exam, then run them on makeshift Python scripts duct-taped together over a weekend.
Agent infrastructure means everything that supports an AI agent’s operation beyond the model itself: the servers, databases, API connections, error handlers, logging systems, and state managers that let an agent actually execute tasks in the real world. It’s the plumbing, not the water.
Under the hood, agent infrastructure handles:
- Routing requests between models and tools
- Managing conversation history and context windows
- Authenticating with external services
- Retrying failed operations with exponential backoff
- Storing intermediate results for later use
Think of it like a restaurant kitchen. The model is the head chef—brilliant, creative, full of ideas. Infrastructure is everything else: the prep cooks, the dishwashers, the inventory system, the fire suppression equipment, the ticket printer. A great chef can’t serve a meal in a kitchen without infrastructure. But a competent chef with a well-run kitchen? They’ll feed hundreds.
Here’s a concrete example using a simple agent loop:
import openai
import json
def agent_with_infrastructure(user_input):
# Infrastructure handles memory (conversation history)
conversation = load_conversation_history(user_id="abc123")
# Infrastructure handles tool availability
available_tools = [
{"name": "search_web", "description": "Search the internet"},
{"name": "read_file", "description": "Read a local file"}
]
# The model call itself is the smallest part
response = openai.chat.completions.create(
model="gpt-4", # The model
messages=conversation + [{"role": "user", "content": user_input}],
tools=available_tools # Infrastructure provides the tools
)
# Infrastructure handles error recovery
if response.choices[0].finish_reason == "error":
save_checkpoint(user_id="abc123") # Don't lose progress
return retry_with_backoff(user_input)
# Infrastructure persists results for later use
save_intermediate_result(response)
return response
Non-obvious insight: Most agent failures aren’t the model’s fault—they’re infrastructure failures. API rate limits, expired auth tokens, network timeouts, corrupted state. The model never even sees these problems.
Memory: Your Agent’s Glass Bones
Here’s another juxtaposition: models have perfect recall of their training data but forget what they said thirty seconds ago.
Memory in agent systems means the ability to store and retrieve information across interactions—conversation history, user preferences, task progress, intermediate calculations. Without it, every conversation starts from scratch, like talking to someone with anterograde amnesia.
The mechanism works through three layers:
- Short-term memory: The model’s context window (typically 4K-200K tokens)
- Working memory: A structured database of recent interactions
- Long-term memory: Vector databases or key-value stores for persistent knowledge
Analogy time: You’re reading a book. Short-term memory is the page you’re currently looking at. Working memory is the last few chapters you’ve read. Long-term memory is your ability to remember the plot when you pick the book up again next week.
Here’s a practical implementation using a vector database for agent memory:
import chromadb
class AgentMemory:
def __init__(self):
self.client = chromadb.Client()
self.collection = self.client.create_collection("agent_memory")
self.short_term_limit = 4000 # tokens
def remember(self, interaction):
# Store in long-term memory as embeddings
self.collection.add(
documents=[interaction["text"]],
metadatas=[{"timestamp": interaction["timestamp"]}],
ids=[str(interaction["id"])]
)
def recall(self, query, limit=5):
# Semantic search through past interactions
results = self.collection.query(
query_texts=[query],
n_results=limit
)
return results['documents'][0]
The gotcha: Vector database queries are slow compared to in-context memory. Relying on long-term memory for every response adds 100-500ms latency. Smart agent infrastructure caches frequently accessed memories in the context window.
Tool Integration: Teaching Your Agent to Use External Tools
Your model is an expert in every API documentation ever published. But it can’t actually call any of them.
Tool integration means giving an agent the ability to interact with external services, databases, and systems—sending emails, querying databases, posting to Slack, updating spreadsheets. Without tools, your agent is a brilliant consultant who can only give advice but never touch a keyboard.
The mechanism works through “function calling” or “tool use” APIs. The model outputs a structured request (usually JSON) specifying which tool to use and with what parameters. Infrastructure then executes that call and returns the result to the model.
Real-world analogy: You’re a manager delegating work. Your model is the employee who knows what needs to be done. Tool integration is giving them access to the company credit card, the email system, and the key to the supply closet. Knowledge without access produces nothing.
# Defining a tool for the agent to use
tools = [
{
"name": "send_email",
"description": "Send an email to any recipient",
"parameters": {
"type": "object",
"properties": {
"to": {"type": "string", "description": "Recipient email"},
"subject": {"type": "string"},
"body": {"type": "string"}
},
"required": ["to", "subject", "body"]
}
}
]
# The model's response requests a tool call
model_response = {
"tool_calls": [
{
"id": "call_123",
"function": {
"name": "send_email",
"arguments": json.dumps({
"to": "user@example.com",
"subject": "Task complete",
"body": "Your spreadsheet has been updated."
})
}
}
]
}
# Infrastructure executes the tool call
if model_response.get("tool_calls"):
for call in model_response["tool_calls"]:
result = execute_tool(call["function"]["name"],
json.loads(call["function"]["arguments"]))
# Pass result back to model for next step
Edge case: What happens when a tool call fails? Good infrastructure has fallback plans—retry logic, alternative tools, or graceful degradation. Bad infrastructure just crashes the entire agent.
Error Handling: Your Agent’s Nurse
Here’s the most telling juxtaposition: we trust AI agents with customer data, financial transactions, and medical advice, but most agent systems have error handling that would embarrass a PHP script from 2005.
Error handling in agent systems means detecting, categorizing, and recovering from failures at every level—model errors, tool errors, network errors, authentication errors, and logic errors. It’s the safety net that catches your agent when it inevitably makes a mistake.
The mechanism should be multi-layered:
- Retry logic: Automatically retry transient failures (rate limits, timeouts)
- Fallback tools: If one tool fails, try an alternative
- Human handoff: When all else fails, hand off to a human operator
- State preservation: Never lose intermediate progress on failure
import time
from functools import wraps
def retry_with_backoff(max_retries=3, base_delay=1.0):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
for attempt in range(max_retries):
try:
return func(*args, **kwargs)
except RateLimitError:
if attempt == max_retries - 1:
raise # Give up after max retries
delay = base_delay * (2 ** attempt) # Exponential backoff
print(f"Rate limited. Retrying in {delay}s...")
time.sleep(delay)
except AuthTokenExpired:
refresh_auth_token() # Auto-recover auth issues
except ToolTimeoutError:
return {"error": "tool-timeout", "fallback": "manual"}
return wrapper
return decorator
@retry_with_backoff()
def call_agent(user_input):
return model.chat([{"role": "user", "content": user_input}])
Non-obvious insight: Most agent frameworks hide errors. They catch exceptions and return “I’m sorry, I couldn’t complete that task.” This is dangerous. Good infrastructure surfaces failures clearly so developers can improve the system, not sweep problems under the rug.
Observability: Seeing Inside Your Agent
Your agent is a black box. It takes input, produces output, and you have no idea what happened in between.
Observability in agent systems means structured logging, tracing, and monitoring of every decision, tool call, and state change an agent makes. It’s the difference between a mechanic diagnosing your car with a diagnostic computer vs. blindly replacing parts.
The mechanism involves:
- Structured logging: Every model call, tool invocation, and error logged with timestamps
- Traces: End-to-end tracking of a single user request through all its steps
- Metrics: Success rates, latency percentiles, token usage, tool call frequencies
import structlog
logger = structlog.get_logger()
async def agent_with_observability(user_input):
with logger.new_context(request_id=generate_uuid()):
logger.info("agent.start", input=user_input[:100]) # Log truncated input
try:
model_response = await call_model(user_input)
logger.info("model.response",
tokens=model_response.usage.total_tokens,
finish_reason=model_response.finish_reason)
if model_response.tool_calls:
for call in model_response.tool_calls:
logger.info("tool.call",
name=call.function.name,
args=call.function.arguments)
result = await execute_tool(call)
logger.info("tool.result", success=result.success)
logger.info("agent.complete", duration_ms=time_ms())
return model_response
except Exception as e:
logger.error("agent.failure", error=str(e), trace=traceback.format_exc())
raise
Comparison Table: Models vs. Infrastructure
| Aspect | Models | Infrastructure |
|---|---|---|
| What it is | Neural network that generates text | Everything that supports the model |
| Bottleneck | Reasoning capability | Reliability and speed |
| Failure mode | Gives wrong answer | Never gets to answer |
| Development focus | Training more data, bigger networks | Building robust pipelines, error handling |
| Debug difficulty | Hard (black box) | Easier (deterministic components) |
| User impact | Quality of output | Whether output arrives at all |
| Cost center | GPU compute for training | Server costs, API calls, storage |
Key Takeaways
- Agent infrastructure is the difference between a demo and a product. Models give you capability; infrastructure gives you reliability.
- Memory systems must be layered. Short-term for speed, long-term for persistence, working memory for the last few interactions.
- Tools are the agent’s hands. Without tool integration, your agent can talk but never act.
- Error handling is non-negotiable. Every agent system needs retry logic, fallbacks, and human handoff paths.
- Observability isn’t optional. You can’t improve what you can’t see. Log every decision, every call, every failure.
- Most agent failures are infrastructure failures. Before blaming the model, check your rate limits and auth tokens.

Comments