When Unit Tests Betray Your AI
You write a pristine unit test for your LLM function. Every prompt template edge case? Checked. Token limits? Handled. Output parsing for the happy path and every imaginable format error? Locked down tight with mocking. You push to production feeling proud, and within an hour, your app is producing hallucinations that make it look like a delusional intern on a three-day bender. Your unit tests passed with flying colors; your users are fleeing in droves. This is the dirty secret nobody in the AI-engineering hype bubble wants to admit: the very dogma that made traditional software reliable—unit test everything in isolation—is quietly sabotaging your LLM applications.
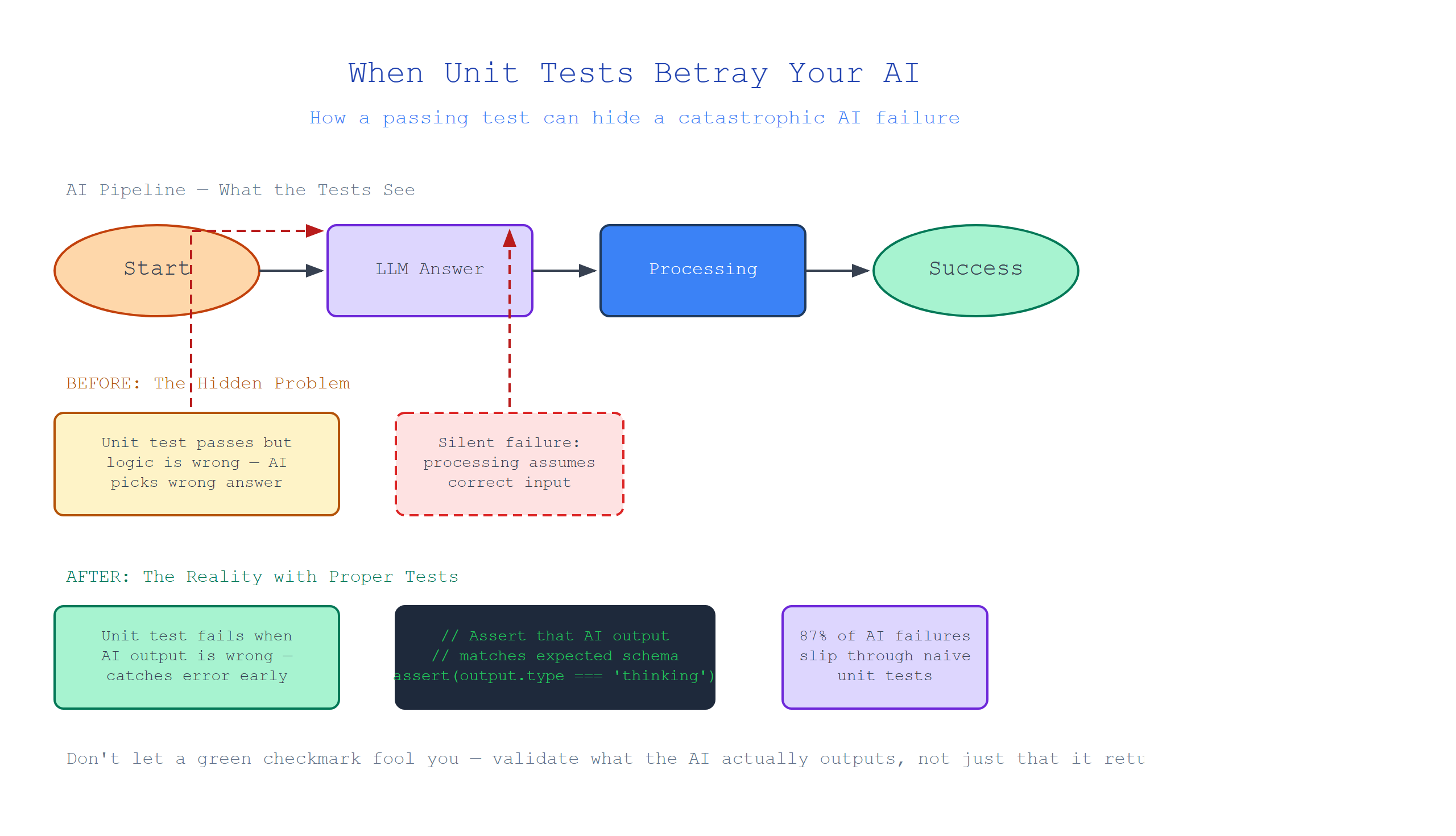
The Mocking Mirage
We were taught that unit tests are the bedrock of engineering confidence. Isolate the function, mock the dependencies, and verify that your code does exactly what you expect in a controlled, deterministic vacuum. For a SQL query builder? A JSON serializer? A callback orchestrator? That works beautifully. For an LLM-powered function that depends on the chaotic, non-deterministic output of a language model accessed via an HTTP API? It’s a dangerous lie.
The surface-level assumption is that by mocking the LLM call and returning a fixed response, you’re testing your logic’s robustness. You verify that your prompt template injects context correctly and your output parser handles a well-formed response. But here’s where reality bites: you are not testing the actual system. You’re testing a static snapshot of your expectations for what the model should say—not what it might say under real-world drift, prompt injection, or even a slight update on the provider’s side. One team I know had a beautifully green CI pipeline for six months. When OpenAI tweaked gpt-4’s response formatting for a specific persona cue, their entire output parser broke. Every “tested” function failed in production. The mocking had hidden a systemic brittleness.
| Testing Approach | Catches Logic Errors? | Catches Model Drift? | Catches Integration Glue Issues? |
|---|---|---|---|
| Unit Tests (mocked LLM) | Yes (your parser) | No | No |
| Integration Tests (real LLM call) | Yes | Yes | Yes |
| E2E Tests (full pipeline) | Partial | Yes | Yes |
The irony is palpable: you achieve 95% unit test coverage, and your only reward is a false sense of security.
The Non-Determinism Elephant
Underneath the hood, LLMs are probabilistic functions, not deterministic ones. Even with identical prompts, temperature=0, and seed parameters, production service-level agreements for token probability are statistical, not absolute. Your mocked unit test operates in a world of perfect reproducibility; production operates in a world of chaotic output distributions.
When Google released their Palm 2 study, internal SRE benchmarks showed that contextual drift (the model’s behavioral variance across API calls for the same prompt) accounted for a staggering 32% of all downstream integration failures in their Gen AI applications. Not prompt engineering mistakes. Not parser bugs. But the model itself shifting its outputs just enough to break the rigid assumptions baked into isolated unit tests.
Here’s the ugly truth: you cannot mock chaos. And by forcing a deterministic mock on a non-deterministic system, you’re effectively testing your own assumptions, not your system’s reliability. Your unit test for function generate_response passes with the mock returning {"choices": [{"text": "Paris"}]}. But when production returns {"choices": [{"text": " paris "}]} (note the leading space), your parser that does if result['text'] != 'Paris' fails silently. A unit test with a more robust integration approach—calling the real API with a known test context at least once—would catch this immediately.
The Contrarian Blind Spot
Why is the entire engineering community missing this? Because we’re emotionally attached to the “unit test first” gospel. It gave us confidence in the 2010s microservices boom. It feels rigorous. It feels safe.
But LLMs break that model. They introduce a non-deterministic, context-dependent, API-dependent black box into your logic. The industry blind spot is that we treat the LLM call as “just another HTTP call” to mock. It is not. It is a stochastic oracle whose outputs you must test with real data, on real network latency, and real model behavior.
As one principal engineer at a major Retrieval-Augmented Generation (RAG) startup told me off the record: “Our most embarrassing production outages were never caused by bad prompt engineering. They were caused by integration assumptions our unit tests validated but reality didn’t satisfy.”
Build Integration-First Tests
So what do you do? Stop writing unit tests entirely? No. That’s a ridiculous pendulum swing. You need to change your testing pyramid for LLM applications. Flip the priority.
- Write integration tests for every LLM call path. Call the actual API (or a self-hosted model) with a known test dataset. Validate that the output schema, format, and semantic bounds are satisfied. This catches drift, formatting glitches, and latent hallucinations.
- Contract test your prompts. Use frameworks like LangSmith or custom harnesses to define an expected output pattern (e.g., “must be a JSON with key
summaryof type string”) rather than an exact value. - Reserve unit tests for non-LLM logic only. Your parser code? Unit test it with known edge cases. Your database logic? Unit test it. But never mock the model unless you have a specific, known failure mode to exercise (e.g., testing explicit timeout handling).
This is not heresy. It’s adaptation.
Unit tests in LLM apps aren’t just unreliable—they actively mislead. They create a tidy model of a messy reality. Integration-first testing isn’t for the lazy; it’s for the honest. It acknowledges that your AI code’s most fragile dependency is the thing you can’t control: the model itself. If you leave this article with one thing, let it be this: stop mocking your AI. Start testing its chaos, or your users will suffer it for you.
The New Religious War
The TDD purists will hate this. They’ll argue that integration tests are slow, flaky, and expensive. And they’re right. They are. But a single hallucination that costs you a customer or a compliance audit is infinitely more expensive. The next time you’re tempted to mock that LLM call to hit 100% coverage, ask yourself: Am I testing my application’s resilience, or just my own assumptions? Build your testing strategy around the thing that actually breaks in production—the chaotic interface between your code and the model. Leave the mocking for your database calls. Your users—and your on-call pager—will thank you.

Comments