Extending Agents with Graph-Powered Reasoning and Neo4j
layout: default title: “Extending Agents with Graph-Powered Reasoning and Neo4j” date: 2025-05-26
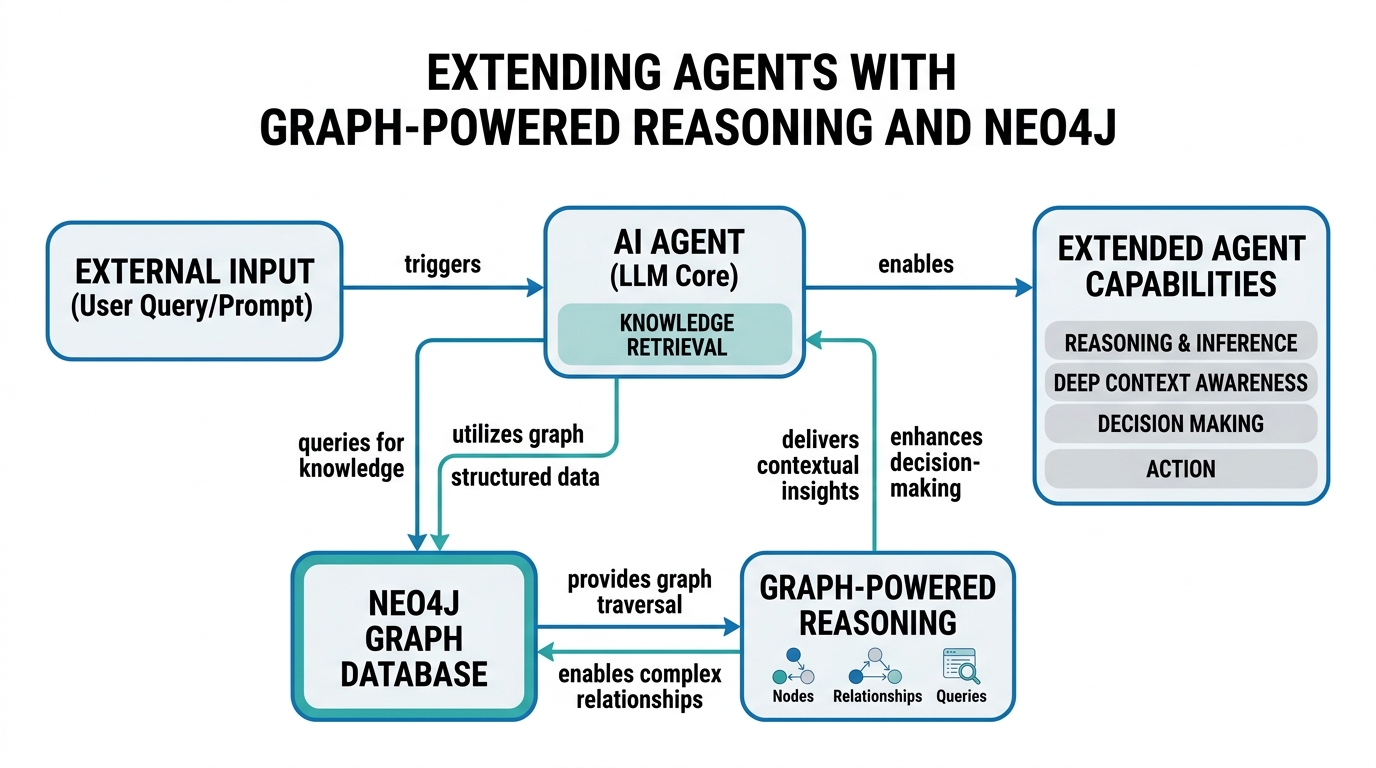
Let’s be honest: most AI agents today have the memory of a goldfish and the reasoning skills of a toddler with a crayon. They can repeat facts, sure, but ask them to connect dots across a web of relationships, and they crumble. That’s where graph databases come in. By pairing agents with a Neo4j knowledge graph, you give them a structural memory that goes way beyond flat text files. They stop guessing and start reasoning through relationships.
In this tutorial, you’ll learn exactly how to do that. We’ll demystify graph databases, Neo4j, relationship-aware reasoning, agent lookups, knowledge graphs, and relational data mapping. No buzzwords, no magic—just clear definitions, an analogy for each concept, and code you can run today.
Graph Databases: Not Just More Tables
Graph databases store data in nodes and relationships, not rows and columns. Think of a node as a person, and a relationship as the line connecting them—”knows,” “works with,” “owns.” A graph database prioritizes these connections, making relationship queries lightning-fast.
Under the hood, instead of scanning massive tables and joining them (the SQL way), a graph database follows pointers from one node to the next. It’s like walking through a city using a map with roads, rather than a spreadsheet of street names and coordinates.
Analogy: Imagine a family tree. A spreadsheet would list every person and their parents. To find your great-grandfather, you’d have to run multiple lookups. A graph database just walks up the “parent” relationship one step at a time—it’s intuitive and fast.
Code Example:
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "password"))
def find_knows(tx, name):
query = """
MATCH (p:Person {name: $name})-[:KNOWS]->(friend)
RETURN friend.name
"""
result = tx.run(query, name=name)
return [record["friend.name"] for record in result]
with driver.session() as session:
friends = session.read_transaction(find_knows, "Alice")
print(f"Alice knows: {friends}")
This code asks the database: “Give me everyone who is directly connected to Alice via a KNOWS relationship.” No joins, no table scans—just a fast pointer traversal.
Non-obvious insight: Graph databases look easy, but schema design is critical. If you don’t define relationship types clearly, you’ll get slow queries and confusing results. Always model your domain first.
Neo4j: The Graph Database Powerhouse
Neo4j is the most popular graph database. It’s open-source, uses Cypher (a declarative query language), and handles millions of relationships easily. It’s what makes graph-powered agents practical.
Under the hood, Neo4j stores data in a native graph format. Each node stores direct pointers to its relationships and properties. This is different from a relational database, which stores data in tables and uses indexes to find connections.
Analogy: Imagine a library catalog. A relational database is a giant spreadsheet where each book is a row, and you find books by scanning columns. Neo4j is a web of interconnected bookmarks—each book points directly to its author, genre, and related titles.
Code Example:
def add_person_and_knows(tx, name1, name2):
query = """
MERGE (a:Person {name: $name1})
MERGE (b:Person {name: $name2})
MERGE (a)-[:KNOWS]->(b)
"""
tx.run(query, name1=name1, name2=name2)
with driver.session() as session:
session.execute_write(add_person_and_knows, "Charlie", "Diana")
This creates two nodes and a KNOWS relationship between them. MERGE ensures we don’t create duplicates—a common gotcha that beginners miss.
Knowledge Graphs: Building the Agent’s Brain
A knowledge graph is a database of entities (nodes) and their relationships, designed to capture real-world meaning. It’s the brain your agent can query for structured understanding.
How it works: You define entities (people, places, concepts) and link them with typed relationships (“lives in,” “invented by,” “part of”). The result is a network of facts the agent can traverse to find answers.
Analogy: Think of Wikipedia’s infoboxes. For “Albert Einstein,” you’d see “born in Ulm,” “known for relativity,” “studied at ETH Zurich.” That’s a mini knowledge graph.
Code Example:
def create_knowledge_graph(tx):
queries = [
"CREATE (e:Entity {name: 'Albert Einstein', birth: 1879})",
"CREATE (e:Entity {name: 'Theory of Relativity', type: 'concept'})",
"MATCH (a:Entity {name: 'Albert Einstein'}), (b:Entity {name: 'Theory of Relativity'}) CREATE (a)-[:KNOWN_FOR]->(b)"
]
for q in queries:
tx.run(q)
with driver.session() as session:
session.execute_write(create_knowledge_graph)
Non-obvious insight: Your knowledge graph is only as good as your relationship types. Vague relationships like “related to” are useless. Be specific.
Relationship-Aware Reasoning: Connecting the Dots
Relationship-aware reasoning means an agent uses the connections between concepts (not just their individual attributes) to make decisions. It’s reasoning with context.
How it works: The agent queries the graph for paths, patterns, or neighborhoods. Instead of asking “What is a car?” it asks “What nodes are connected to ‘engine’ via ‘part_of’ relationships?” This gives it structural understanding.
Analogy: You don’t just know that a “key” exists. You know it opens a door, which leads to a room, which contains a treasure. That chain of reasoning is relationship-aware.
Code Example:
def find_second_degree_contacts(tx, name):
query = """
MATCH (p:Person {name: $name})-[:KNOWS*2]->(contact)
WHERE NOT (p)-[:KNOWS]->(contact)
RETURN DISTINCT contact.name
"""
result = tx.run(query, name=name)
return [record["contact.name"] for record in result]
This finds people who are “friends of friends” but not direct friends. The agent reasons: “If Alice knows Bob, and Bob knows Charlie, then Alice might want to meet Charlie.”
Agent Lookups: Serving the Graph to Your Agent
Agent lookups is how your agent interacts with the graph—sending queries and using the results to inform its next action.
How it works: The agent sends a Cypher query to Neo4j, receives structured JSON back, and processes it. No string matching, no vector search—just precise graph traversals.
Analogy: You (the agent) ask a librarian (the database) for “books by authors born before 1900.” The librarian doesn’t guess; they walk the shelves and hand you the exact list.
Code Example:
def agent_get_suppliers(tx, product_name):
query = """
MATCH (p:Product {name: $product_name})<-[:SUPPLIES]-(s:Supplier)
RETURN s.name, s.location
"""
result = tx.run(query, product_name=product_name)
return [{"name": r["s.name"], "location": r["s.location"]} for r in result]
Non-obvious insight: Keep queries simple. Complex multi-hop queries can confuse your agent. If your graph is well-modeled, even single-hop lookups give rich context.
Relational Data Mapping: From Tables to Graphs
Relational data mapping is the process of taking data from traditional SQL tables and converting it into a graph structure. It’s how you make existing data graph-ready.
How it works: you identify entities (tables become node types) and relationships (foreign keys become relationship types). Then you write transformation scripts to migrate the data.
Analogy: You have a pile of LEGO bricks (tables) and want to build a castle (graph). First, you sort the bricks by color and shape (entities), then you figure out how they connect (relationships).
Code Example:
def migrate_customers_from_sql():
import sqlite3
sql_conn = sqlite3.connect("old_data.db")
cursor = sql_conn.cursor()
cursor.execute("SELECT id, name, city FROM customers")
with driver.session() as session:
for row in cursor:
session.run(
"MERGE (c:Customer {id: $id, name: $name, city: $city})",
id=row[0], name=row[1], city=row[2]
)
Non-obvious insight: Watch for one-to-many relationships in SQL. A single customer might have multiple orders—in the graph, this becomes multiple :ORDERED relationships from one customer node.
Summary: How It All Connects
| Concept | What It Is | Why It Matters |
|---|---|---|
| Graph Database | Stores data as nodes & relationships | Fast relationship queries |
| Neo4j | Popular graph DB that uses Cypher | Practical tool for building agents |
| Knowledge Graph | A graph of real-world entities & connections | Gives agents structured understanding |
| Relationship-Aware Reasoning | Using graph connections for decision-making | Contextual, not just factual |
| Agent Lookups | How agents query the graph for information | Enables directed, precise memory retrieval |
| Relational Data Mapping | Converting SQL tables to graph nodes/edges | Brings existing data into the graph |
Key Takeaways
- Graph databases store data as networks, making relationship queries fast and natural.
- Neo4j is the go-to tool for building graph-powered agents; learn Cypher basics.
- Knowledge graphs give agents a structured, real-world memory.
- Relationship-aware reasoning lets agents make decisions based on connections, not just facts.
- Agent lookups with Cypher are precise and easy to implement.
- Relational data mapping helps you reuse existing data in a graph format.
Now go connect some dots.

Comments