Making LLMs Faster: A Practical Guide to Speculative Decoding and Structured Outputs
Large language models are incredible, but they have a dirty secret: they’re painfully slow. If you’ve ever waited endlessly for a model to generate a simple JSON response, you know the frustration. The good news? We don’t have to live with it. By understanding two powerful optimization techniques—speculative decoding and constraint decoding—we can dramatically speed up inference while maintaining, or even improving, output quality.
In this guide, you’ll learn how these techniques work under the hood, using real-world analogies and code examples with Qwen and DeepSeek models. We won’t just scratch the surface; we’ll explore the mechanisms, edge cases, and practical implementation details that most tutorials skip. By the end, you’ll know exactly how to optimize your LLM-powered applications for speed and reliability.
Understanding Inference Optimizations
Inference optimizations are techniques that reduce the time and computational cost of running a model to generate predictions. They’re not about making the model smarter—they’re about making it work faster.
How it works: Every token (word or subword) generated by an LLM requires a forward pass through the entire network. This is expensive. Optimizations reduce the number of passes or the cost per pass without significantly degrading output quality.
Analogy: Think of it like cooking. A standard recipe takes 30 minutes. Inference optimizations are like pre-chopping your vegetables (batch processing), using a faster oven (better hardware), or preparing two dishes at once (parallel generation). The food tastes the same, but it gets to the table faster.
Code example:
# Without optimization: generate tokens one at a time
generated = []
for _ in range(100):
token = model.generate_next_token(generated)
generated.append(token)
# With optimization: batch multiple contexts
batch = ["What is AI?", "Explain ML", "What are transformers?"]
responses = model.batch_generate(batch)
Non-obvious insight: Many optimizations, like speculative decoding, trade memory for speed. They’re most effective on larger models where the memory overhead is small relative to the computational savings. For small models, the overhead can actually slow things down.
The Rise of Open-Source LLMs
Open-source LLMs are models whose weights, architecture, and training code are publicly available. Unlike proprietary models (GPT-4, Claude), you can download, modify, and run these models on your own hardware.
How it works: Companies like Alibaba (Qwen) and DeepSeek (DeepSeek) release their model weights under open licenses. This means you can run them locally, fine-tune them for specific tasks, and inspect their inner workings.
Analogy: Open-source LLMs are like having a Michelin-star chef’s recipe book. You don’t just order from the menu—you can cook the dish yourself, tweak ingredients, and understand exactly why it works. Proprietary models are like that chef’s secret menu: delicious, but you can’t modify or analyze it.
Code example:
from transformers import AutoModelForCausalLM, AutoTokenizer
# DeepSeek: efficient for long contexts
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct")
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct")
# Qwen: strong general performance
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-7B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
Non-obvious insight: Not all open-source models are equally optimizable. DeepSeek’s architecture is inherently more efficient for long-context tasks due to its use of Multi-Query Attention. This interacts differently with inference optimizations than Qwen’s architecture.
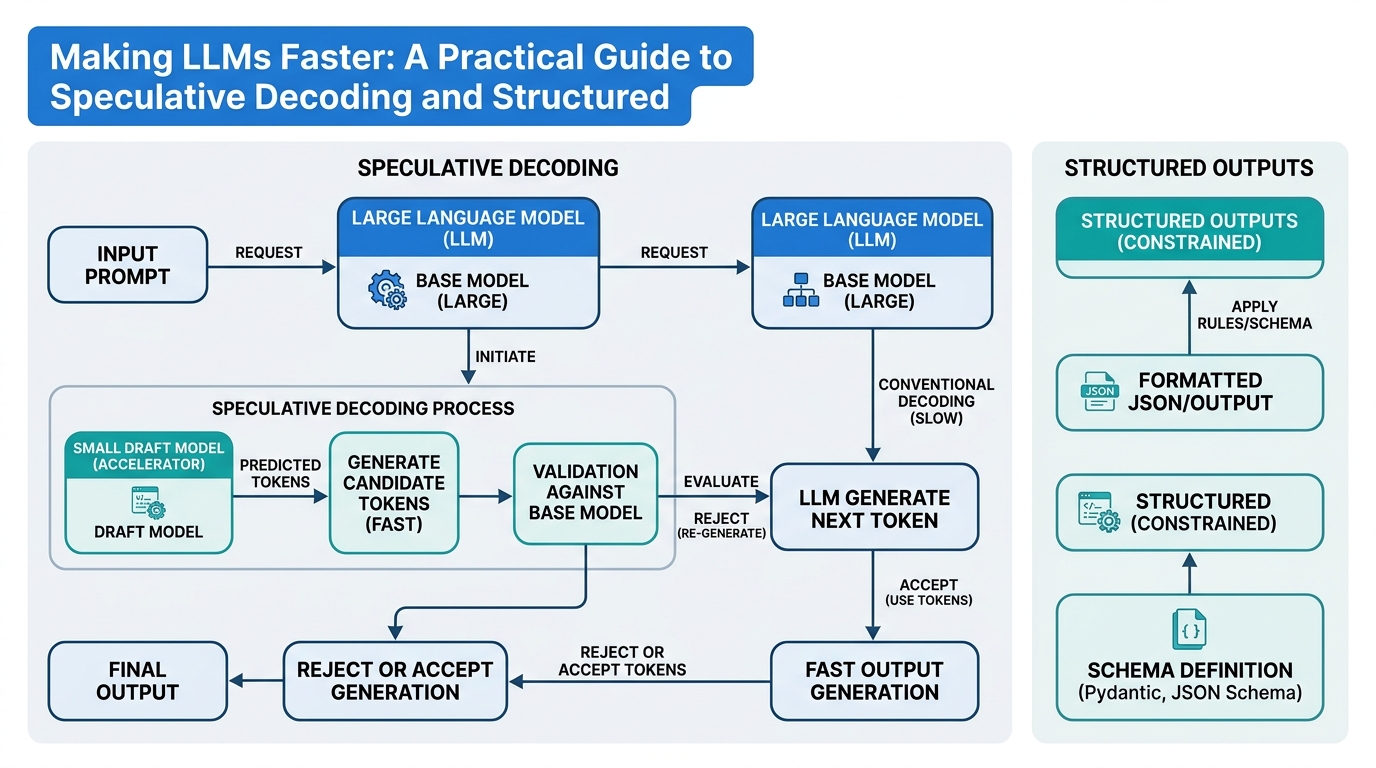
Speculative Decoding: Drafting Faster
Speculative decoding is a technique where a smaller, faster “draft” model generates multiple candidate tokens, and a larger “target” model verifies them in parallel. If the draft tokens are correct, they’re accepted immediately. If not, the target model corrects the mistake.
How it works: The draft model generates K tokens one at a time (fast). The target model then evaluates all K tokens in a single forward pass (parallel). Tokens with high probability are accepted; the first rejected token and subsequent ones are discarded, and the process restarts from the last accepted token.
Analogy: Imagine proofreading a document. Instead of writing and immediately checking each word (slow), you write a whole paragraph quickly (draft), then have an editor check it all at once (verify). If it’s good, you save time. If there are mistakes, you only lose the work on the bad section.
Code example:
from speculative_decoding import SpeculativeDecoder
# Qwen is the target, small model is the draft
decoder = SpeculativeDecoder(
target_model="Qwen/Qwen2-7B-Instruct",
draft_model="Qwen/Qwen2-0.5B-Instruct",
num_draft_tokens=5 # How many tokens the draft generates
)
generated = []
input_ids = tokenizer("Explain the water cycle:", return_tensors="pt").input_ids
while len(generated) < 200:
# Step 1: Draft generates 5 candidate tokens
# Step 2: Target verifies all 5 in parallel
# Step 3: Accepted tokens are appended
accepted_tokens = decoder.step(input_ids)
generated.extend(accepted_tokens)
# If all 5 accepted, tokens appear to be generated 5x faster
# If 0 accepted, we actually regress
print(tokenizer.decode(generated))
Non-obvious insight: Speculative decoding’s efficiency depends on the draft model’s accuracy. A draft model that’s too weak will have many rejections, making the process slower than standard generation. There’s a sweet spot where the draft is ~70% accurate on the first few tokens. Most tutorials skip this practical tuning step.
Constraint Decoding: Forcing Structure
Constraint decoding is a technique that enforces a specific output format during generation, such as valid JSON or a regex pattern. Instead of hoping the model follows instructions, you actively prevent it from producing invalid tokens.
How it works: At each generation step, you maintain a finite state machine (FSM) representing allowed next tokens based on the desired format. Tokens outside the allowed set are masked (their probability set to zero), forcing the model to produce valid output.
Analogy: Constraint decoding is like using a stencil to paint. You don’t have to carefully paint within the lines—the stencil (FSM) physically blocks paint from going outside the allowed area. You get a perfect result every time, even if you’re sloppy.
Code example:
from constrained_decoding import create_regex_constraint
# Define the desired output format
pattern = r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}" # IP address
# Create constraint that ensures valid IP generation
constraint = create_regex_constraint(tokenizer, pattern)
input_text = "Generate a random IP address: "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
for _ in range(100):
logits = model(input_ids).logits[:, -1, :]
# Apply constraint: mask invalid tokens
allowed_tokens = constraint.get_allowed_tokens(input_ids)
mask = torch.full_like(logits, -float('inf'))
mask[:, allowed_tokens] = 0
logits = logits + mask
# Sample from constrained distribution
next_token = torch.multinomial(F.softmax(logits, dim=-1), 1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
output = tokenizer.decode(input_ids[0])
print(output) # Guaranteed valid IP format
Non-obvious insight: Constraint decoding works well only when the constraint is lexicographic (character-by-character). For semantic constraints (like “must relate to climate change”), you need a different approach entirely. Most tutorials conflate these two types of constraints.
Structured Outputs: The Marriage of Speed and Reliability
Structured outputs combine constraint decoding with output formatting to guarantee that model responses follow a specific schema (JSON, YAML, etc.) while maintaining speed through inference optimizations.
How it works: You define a schema (e.g., using Pydantic or JSON Schema), convert it to a constraint that the model must follow during generation, and apply speculative decoding to speed up the process. The result is fast, validated output.
Example: For a weather API, you want responses in this JSON format:
{
"city": "San Francisco",
"temperature": 72.5,
"units": "Fahrenheit",
"forecast": ["sunny", "cloudy"]
}
With structured outputs:
from structured_outputs import SchemaConstraint, StructuredGenerator
# Define the schema
schema = {
"type": "object",
"properties": {
"city": {"type": "string"},
"temperature": {"type": "number"},
"units": {"type": "string", "enum": ["Fahrenheit", "Celsius"]},
"forecast": {"type": "array", "items": {"type": "string"}}
},
"required": ["city", "temperature", "units"]
}
# Create structured generator with optimized decoding
generator = StructuredGenerator(
model="Qwen/Qwen2-7B-Instruct", # or DeepSeek
constraint=SchemaConstraint(schema),
use_speculative_decoding=True
)
# Generate valid JSON in roughly half the time
response = generator.generate("What's the weather in San Francisco?")
print(response) # Guaranteed valid JSON, follows the schema
Comparison: When to Use What
| Technique | What It Does | Best For | Trade-off |
|---|---|---|---|
| Speculative Decoding | Draft then verify | General text generation with consistent style | Memory overhead; requires accurate draft model |
| Constraint Decoding | Enforce format | JSON, API responses, regex patterns | Only works for lexical constraints |
| Structured Outputs | Combined approach | Production APIs needing speed + reliability | Complex setup; may reduce flexibility |
Summary: Use speculative decoding when speed matters and you don’t need specific formats. Use constraint decoding when format matters and speed is secondary. Combine them (structured outputs) for production systems that need both.
Key Takeaways
- Inference optimizations reduce generation time by batching or predicting more efficiently
- Open-source LLMs let you inspect and modify models for specific optimization needs
- Qwen and DeepSeek are excellent open-source models with different architectural strengths
- Speculative decoding uses a cheap draft model to speed up expensive target models by 2-3x
- Constraint decoding forces valid output by masking illegal tokens during generation
- Structured outputs combine both techniques for fast, guaranteed-valid responses
- The real skill lies not in knowing these techniques, but in knowing when to apply each one
Remember: the best optimization is the one you don’t need. Understand your use case, measure your bottlenecks, then apply the right tool. Your users will thank you for the speed—and your debugging sessions will thank you for the structure.

Comments