On-Premises and Edge AI: Balancing Privacy and Cloud-Edge Compute
You’ve probably heard the hype: AI is moving to the edge, privacy is paramount, and the cloud isn’t always the answer. But what does any of that actually mean for a software engineer building real systems? This tutorial strips away the buzzwords. You’ll walk away with a clear, working understanding of six core concepts: On-Premises Deployment, Edge Devices, Hybrid Model, Data Privacy, Operational Compliance, and Cloud-Edge Coordinated Compute. We’ll define each term in plain English, show you how it works under the hood, and give you concrete code examples you can adapt. No jargon left unexplained.
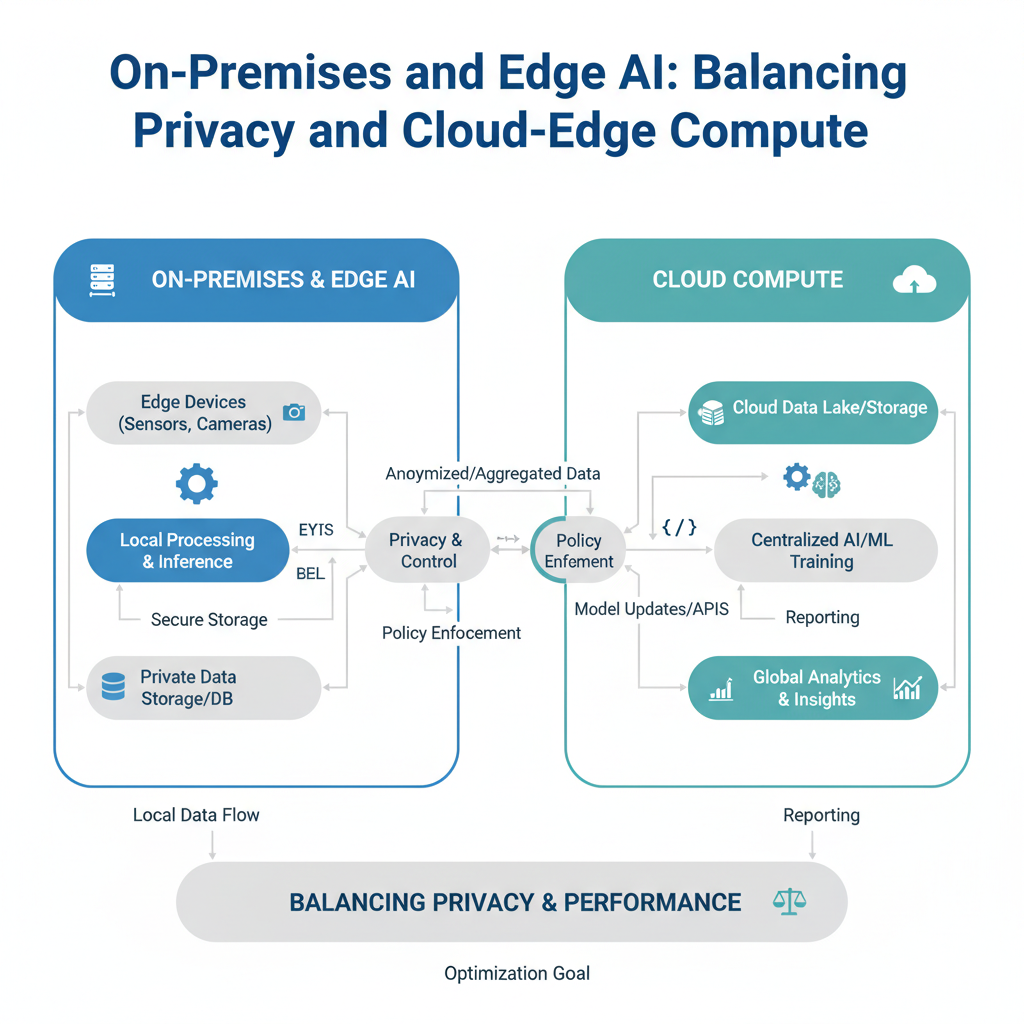
On-Premises Deployment: Your Servers, Your Rules
Plain-English definition: On-premises deployment means running your AI software on hardware you physically own and control, inside your own building. You buy the servers, plug them in, and maintain them yourself.
How it works under the hood: You install your AI model (a trained neural network, for example) on a server in your data center. All data stays within your network — it never travels to a third-party cloud provider’s infrastructure. Inference requests hit your local server, process locally, and return results without leaving your control.
Real-world analogy: Think of a restaurant that grows its own vegetables in a backyard garden. No supply chain, no middleman, no risk of contamination from an outside source. You control the seed, the soil, and the harvest.
Annotated code snippet: Let’s say you have a trained TensorFlow model. Deploying it on-premises might look like this:
# Load your trained model from a local file
import tensorflow as tf
model = tf.keras.models.load_model('/app/models/my_ai_model.h5')
# Inference on incoming data (simulating a request)
def predict_on_premises(input_data):
# input_data is a numpy array or tensor
prediction = model.predict(input_data)
return prediction
# Example usage
sample_input = [[0.5, 0.2, 0.9]] # local data
result = predict_on_premises(sample_input)
print(f"On-premises prediction: {result}")
Expert insight: The gotcha most people miss: on-premises means you own the full hardware lifecycle. Hardware fails, and you need spare parts and redundancy. Cloud providers handle this for you; on-prem, you’re the on-call technician.
Edge Devices: AI at the Very Edge
Plain-English definition: Edge devices are small, often low-power hardware that runs AI models directly where data is collected — think security cameras, smart sensors, or even a Raspberry Pi in a factory. The model processes data locally, without sending it to a central server or the cloud.
How it works under the hood: You compress and optimize your AI model (using tools like TensorFlow Lite or ONNX Runtime) so it can run on a device with limited memory and compute. The device captures data (e.g., a camera feed), runs inference on-device, and only sends results (e.g., “person detected”) when needed. This is super low latency because the processing is done right at the source.
Real-world analogy: A security guard who checks ID at the door (the edge) instead of phoning headquarters for every single visitor. Faster, cheaper, and respects privacy.
Annotated code snippet: Using TensorFlow Lite on a Raspberry Pi:
import tflite_runtime.interpreter as tflite
# Load the optimized model
interpreter = tflite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
# Get input and output tensors
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Capture an image from a camera (simplified)
input_data = capture_camera_frame() # returns numpy array
# Run inference on the edge device
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
print(f"Edge inference result: {output_data}")
Expert insight: Model quantization is the secret sauce. Converting from float32 to int8 can shrink the model 4x and speed up inference 2-3x, but you might lose a tiny bit of accuracy. Testing is critical.
Hybrid Model: The Best of Both Worlds
Plain-English definition: A hybrid model combines on-premises or edge processing with cloud compute. Simple, low-latency tasks run locally; complex or infrequent tasks offload to the cloud.
How it works under the hood: You define a routing logic. For example, a face recognition system might match against a local database of known employees at the edge (fast, private). If no match is found, it sends an anonymized thumbnail to the cloud for a more powerful recognition model. This saves bandwidth and keeps sensitive data local.
Real-world analogy: A triage nurse in an ER. They handle minor cuts and fevers themselves. For a heart attack, they call the specialist (cloud).
Annotated code snippet:
def hybrid_inference(input_data, is_sensitive):
if is_sensitive:
# Run on-premises for privacy
return predict_on_premises(input_data)
elif latency_critical(input_data):
# Run on edge for speed
return predict_on_edge(input_data)
else:
# Offload to cloud
return predict_on_cloud(input_data)
Expert insight: A common pitfall is assuming the offloading decision is static. In reality, network conditions, cloud pricing, and model updates should dynamically rebalance the workload. A smart hybrid system adapts.
Data Privacy: Your Data, Your Control
Plain-English definition: Data privacy means ensuring that personally identifiable, sensitive, or proprietary information is never exposed to unauthorized parties, including cloud providers or third parties, during AI processing.
How it works under the hood: Techniques like data anonymization, differential privacy, and federated learning help. At the deployment level, privacy is enforced by architecture: on-prem and edge devices ensure data never leaves your controlled environment. In the cloud, it requires encryption in transit and at rest, plus strict access controls.
Real-world analogy: It’s like keeping your private diary in a locked safe under your bed (on-prem/edge), versus storing it in a bank vault where the bank manager can technically open it (cloud).
Annotated code snippet: A simple data anonymization step before cloud offloading:
def anonymize_data(data):
# Remove sensitive fields
data.pop('ssn', None)
data.pop('name', None)
# Hash identifiers
data['device_id'] = hashlib.sha256(data['device_id'].encode()).hexdigest()
return data
Expert insight: GDPR and HIPAA don’t just care about where data is stored; they care about where it’s processed. Even if you delete the data later, processing it on a cloud server in another jurisdiction can violate compliance.
Operational Compliance: Following the Rules
Plain-English definition: Operational compliance means adhering to legal, regulatory, and industry-specific rules (like HIPAA in healthcare or GDPR in Europe) when deploying and operating AI systems.
How it works under the hood: Compliance is baked into your architecture. For example, if your model processes medical records, you must ensure it runs on infrastructure that is HIPAA-eligible (e.g., dedicated servers on-premises or cloud instances with a Business Associate Agreement). Logs must be auditable, and data retention policies enforced.
Real-world analogy: It’s like a restaurant that follows health codes — not just to avoid a fine, but because the rules exist for a good reason.
Annotated code snippet: A compliance check before cloud offloading:
def check_compliance(region, data_type):
if data_type == 'healthcare' and region != 'us':
raise ValueError("Healthcare data cannot be processed outside US for compliance")
if data_type == 'pii' and region not in ['us', 'eu']:
raise ValueError("PII processing requires US or EU region")
return True
Expert insight: Compliance isn’t a one-time checkbox. Regulations change, and so do your deployments. Automated compliance scanning and regular audits are non-negotiable.
Cloud-Edge Coordinated Compute: The Symphony
Plain-English definition: This is the intelligent orchestration of compute tasks across edge devices, on-premises servers, and cloud resources. The system decides where to run each part of a larger AI workload.
How it works under the hood: A central coordinator (often a lightweight service) monitors latency, bandwidth, compute load, and data sensitivity. It then dispatches tasks accordingly. For example, a video analytics pipeline might do motion detection on the camera (edge), object recognition on an on-premises server, and cross-camera analysis in the cloud.
Real-world analogy: An orchestra conductor who decides which instrument plays when. Each musician (compute node) plays their part, but the conductor ensures the harmony.
Annotated code snippet: A simplified task dispatching service:
def dispatch_task(task_type, data_origin, compute_load):
if compute_load < 10 and not is_sensitive_data(data_origin):
return "edge"
elif compute_load < 100 and is_sensitive_data(data_origin):
return "on_premises"
else:
return "cloud"
Expert insight: State management is the hardest part. If a task is split across edge and cloud, who holds the intermediate state? Stateless designs (sending all context each time) are simpler but waste bandwidth. Stateful designs need distributed state stores that add complexity.
Comparison Table: How They Relate
| Concept | Where Compute Happens | Primary Concern | Typical Use Case |
|---|---|---|---|
| On-Premises | Your data center | Control & Compliance | Processing financial trades |
| Edge Devices | The field (sensor, camera) | Latency & Bandwidth | Real-time defect detection |
| Hybrid Model | Mix of local and cloud | Flexibility & Cost | Smart building security |
| Data Privacy | Architectural enforcement | Trust & Regulation | Healthcare AI |
| Operational Compliance | Rules & Audits | Legal Safety | Insurance claim processing |
| Cloud-Edge Coordinated | Orchestration layer | Efficiency & Scale | Multi-site factory monitoring |
Key Takeaways
- On-Premises Deployment: You control the hardware and data; be ready for maintenance.
- Edge Devices: Low-power, local inference; ideal for latency-sensitive tasks.
- Hybrid Model: Smart routing between local and cloud for cost and performance.
- Data Privacy: Architect your system so sensitive data never leaves your control.
- Operational Compliance: Know the regulations; build compliance into the design, not bolt it on after.
- Cloud-Edge Coordinated Compute: Orchestrate tasks dynamically — it’s a symphony, not a solo.
You now have a solid mental model and concrete code examples to start making informed architecture decisions. The key is to match the compute location to the specific needs of your data, latency, and compliance. Don’t assume the cloud is always the answer; sometimes the best server is the one you own.

Comments