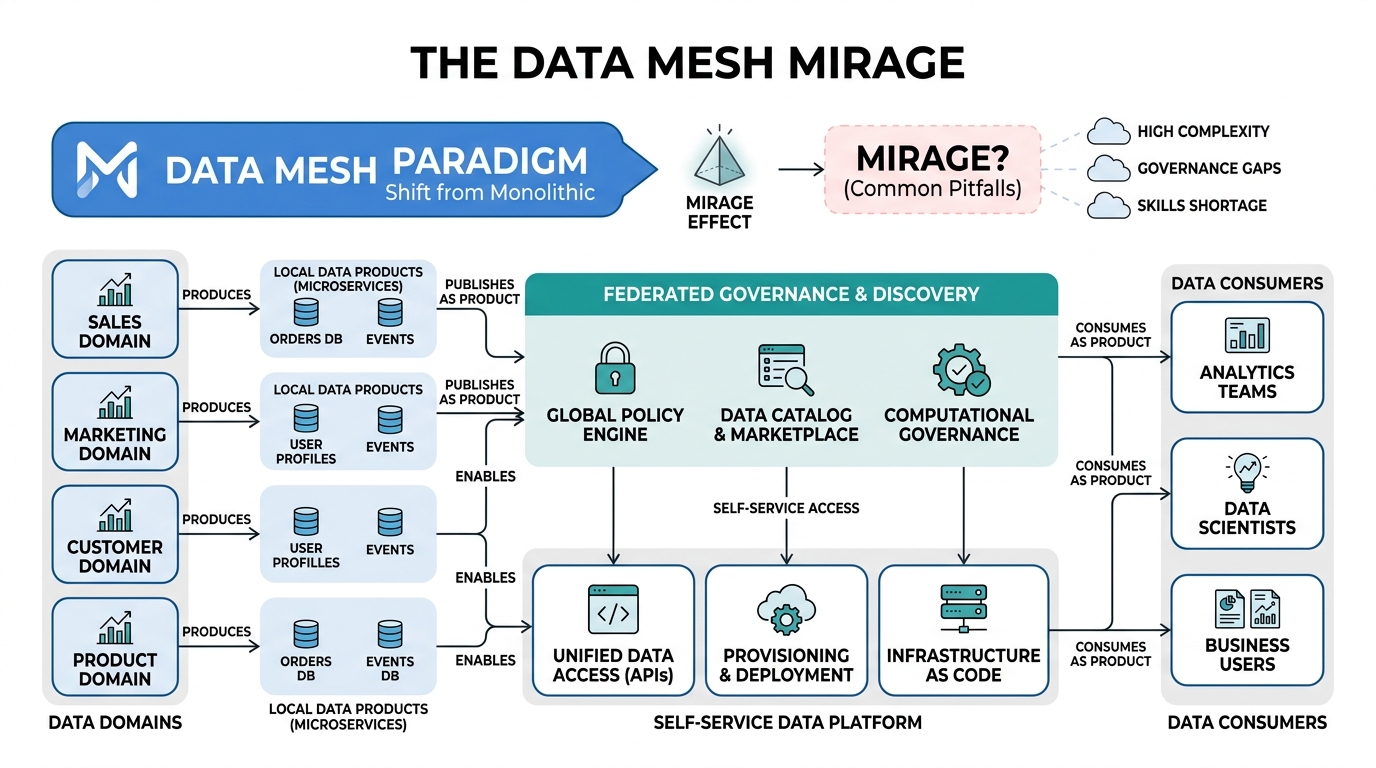
The Data Mesh Mirage
We spent eighteen months and seven figures architecting a glorious data mesh. Then our incident count went up 40% in three months. The irony? Everyone told us decentralization would solve everything. We believed them. We were spectacularly wrong. Not because data mesh is a bad idea in theory. Because the mechanisms that make data reliable are fundamentally at odds with the incentives that drive domain teams. We traded one governance bottleneck for a thousand invisible time bombs.
The Oversell Nobody Talks About
The pitch sounds irresistible. Give data ownership back to the teams who understand it best. Let them define schemas, manage pipelines, serve their own datasets. No more waiting six weeks for the central data team to approve a new column. Freedom. Autonomy. Agility.
What actually happened? Every domain team became a tiny, autonomous data platform. With no platform experience. With no SLA training. With no understanding that a poorly documented schema change at 2:00 AM Tuesday brings down three downstream dashboards, two ML pipelines, and the quarterly board report.
The numbers tell the story. After our mesh rollout, data-related incidents jumped 40% quarter-over-quarter. Mean-time-to-resolve nearly doubled. Why? Because finding the root cause meant spelunking through six different domain-owned data stores, each with its own logging standard — or none at all.
The paradox: Decentralizing ownership decentralizes failure modes, but not accountability. The board still calls the head of data. The head of data can’t fix a broken pipeline in marketing’s domain. They can only watch it burn.
The Hidden Tax of Autonomy
Beneath the surface, something structural is breaking. In a centralized model, you get one data catalog, one schema registry, one set of quality checks. It’s slow. It’s bureaucratic. But it’s consistent. When a column type changes, every consumer knows immediately.
A data mesh replaces one monolithic registry with N autonomous registries. Each domain maintains its own schema, its own quality rules, its own versioning policy. The network complexity grows O(n²) — every domain must interoperate with every consuming domain. The coordination overhead doesn’t disappear. It explodes.
Here’s what surprised me. In our mesh, 60% of incidents came from schema mismatches between domains. Team A introduced a new field. Team B never got the memo. Their ETL silently dropped 15% of records for two weeks before anyone noticed. In the old centralized system, that mismatch would have blocked deployment entirely. That blocking felt like friction. It was actually a safety net.
The mechanism at play is distributed consensus without a shared state. Domain teams don’t have a single source of truth for what data means. They have twelve internal Slack conversations, three notion docs that contradict each other, and a wiki last updated in 2021. Every schema change becomes a bargaining exercise.
Why Proponents Miss the Blatant
Industry blind spots are weirdly specific. The data mesh literature talks endlessly about domain expertise and team autonomy. It barely touches reliability semantics. You’ll find 6,000 words on organizational alignment. Maybe six sentences on what happens when an upstream domain silently drops a required field.
The blind spot comes from cargo-culting microservices wisdom. Microservices succeed at decoupling because they expose well-defined APIs with strict versioning contracts. A data mesh doesn’t expose APIs. It exposes datasets. Datasets have no enforcement mechanism. A service API will reject an invalid payload. A Parquet file with a dropped column will happily corrupt your weekly aggregates until a midnight batch job fails.
Consider this. A domain team ships a schema change on Friday evening. The change is technically backwards-compatible at the data level — they added a nullable field. But their data quality monitoring missed an edge case: the field is always null during their ingest window. Downstream ML pipelines were expecting real values. Training jobs produce garbage metrics for three days.
In a centralized system, one team owns the quality contract. In a mesh, everyone owns their piece. Which means no one owns the whole. The team that broke it doesn’t feel the pain. The team that gets paged at 3:00 AM doesn’t own the root cause.
The Hard Boring Truth
Here’s what I’d tell my past self. Data mesh works when you already have mature data practices. It fails when you use it to skip building those practices. The teams that succeed with mesh already have:
- Central monitoring and SLAs enforced across domains
- A shared contract testing framework for data schemas
- Mandatory backward compatibility windows for schema changes
- A formal incident response process that crosses domain boundaries
Notice what’s missing? The supposed selling point — full domain autonomy — is actively discouraged. Successful meshes operate on a paradox: you decentralize ownership, then centralize everything that makes data reliable. Monitoring. Schema governance. Incident response. Change management.
If you’re contemplating data mesh, ask yourself one honest question: Does your organization already have the tooling and culture to maintain consistent quality across 12 independent teams? If the answer is no, you’re not ready for mesh. You’re ready for a better centralized system with faster feedback loops and less bureaucracy.
- Data mesh decentralized ownership but centralized failure impact — incidents rose 40%.
- The O(n²) coordination overhead of N autonomous registries is the hidden cost no one mentions.
- Schema mismatches caused 60% of incidents; the old centralized system blocked them automatically.
- Decentralization without shared reliability mechanisms is just organized chaos.
- Successful meshes centralize monitoring, schema governance, and incident response.
The real question isn’t whether data mesh is good or bad. It’s whether you’re treating an architectural pattern as a solution for cultural failures. It’s not. You can’t decentralize your way out of bad data hygiene. You can only spread the mess faster. The path forward is boring: build a fast, flexible centralized foundation first. Then, and only then, consider decentralization. Or keep learning the hard way. The choice is yours.

Comments