Understanding Cognitive Loops: Chain-of-Thought and ReAct Logic
You’ve probably asked an AI assistant a complex question and watched it produce a surprisingly thoughtful answer, step by step. But how does that actually work under the hood? In this tutorial, I’ll demystify the internal reasoning mechanisms that make modern LLMs feel genuinely thoughtful. You’ll learn five interconnected concepts: the LLM Central Reasoner, Chain-of-Thought prompting, ReAct Loops, Cognitive Loops, Task Decomposition, and Decision-Making Boundaries. By the end, you’ll understand not just what these terms mean, but how they work together to create sophisticated AI reasoning. No jargon left unexplained. No concept without a concrete example. Let’s start.
The Brain Behind the Curtain
Plain-English definition: The LLM Central Reasoner is the core language model that processes your input and generates responses. It’s the engine, not the fancy steering wheel or dashboard.
How it works: When you send a prompt, the Central Reasoner tokenizes your words, runs them through its neural network (typically a transformer architecture), and predicts the most likely next tokens. It’s doing pattern matching on steroids — billions of parameters calculating probability distributions.
Analogy: Think of the Central Reasoner like a master chef who knows every recipe by heart but needs to be asked the right questions. Give it a vague request like “make food,” and you get whatever random dish pops into its head. Ask it specifically, and you get a masterpiece.
Code example:
from transformers import AutoModelForCausalLM, AutoTokenizer
# The Central Reasoner in action
model_name = "microsoft/phi-2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
prompt = "What's the capital of France?"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
response = tokenizer.decode(outputs[0])
print(response) # "The capital of France is Paris."
The Central Reasoner generates that answer in a single shot. No step-by-step reasoning. No self-correction. Just pure pattern matching from its training data.
Why Single-Shot Answers Fall Short
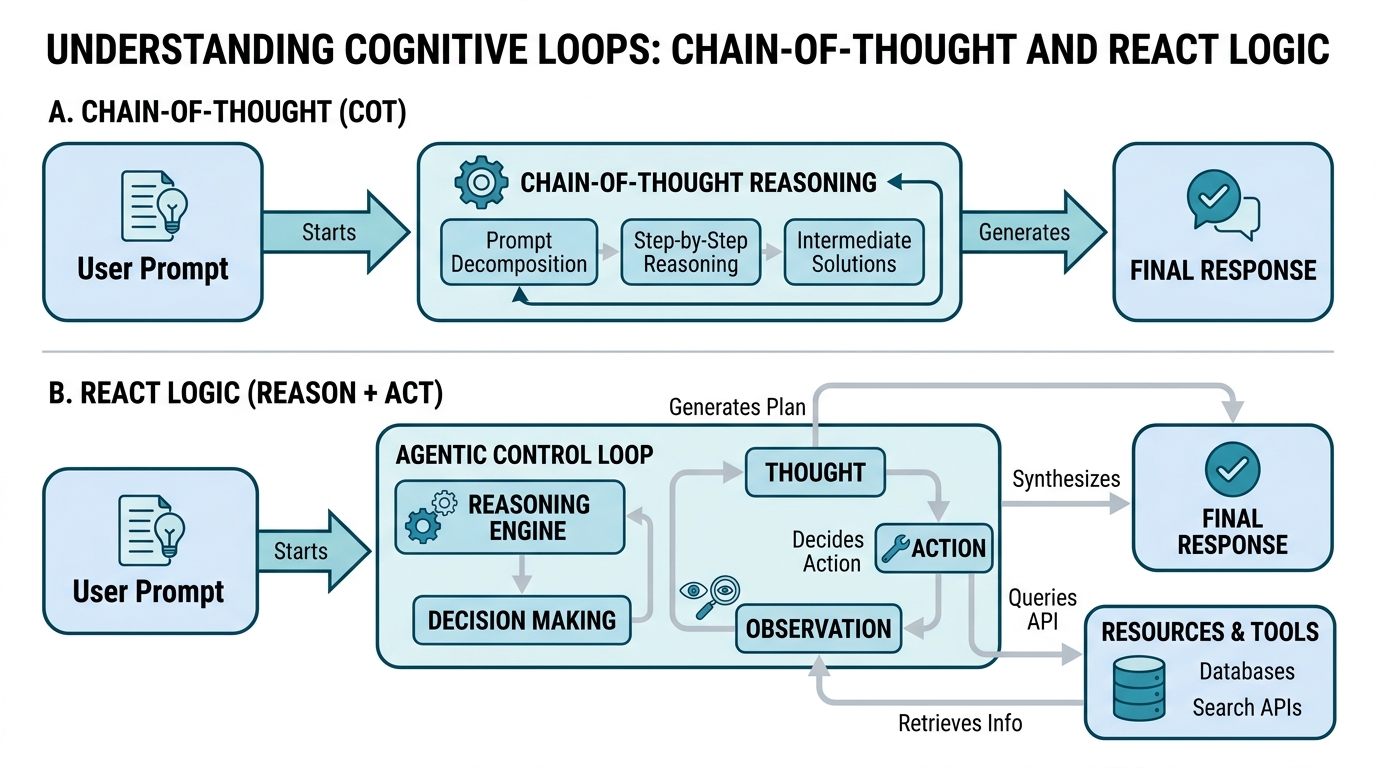
Plain-English definition: Chain-of-Thought (CoT) is a prompting technique that forces the model to show its work, breaking complex problems into a sequence of intermediate reasoning steps before giving the final answer.
How it works: Instead of asking “What is 23 × 47?”, you prompt with “Let’s solve step by step: 23 × 47 = ?” The model then generates intermediate calculations like “23 × 40 = 920” and “23 × 7 = 161” before concluding “1081.” This dramatically improves accuracy on multi-step problems.
Analogy: CoT is like showing your math homework with all the scratch work, not just the final answer. Your teacher (or in this case, the model) catches errors at each step instead of staring at a wrong final number.
Non-obvious insight: CoT doesn’t change the model’s weights. It’s purely a prompting strategy. The same model produces drastically different quality answers depending on whether you ask for direct response or step-by-step reasoning.
# Without Chain-of-Thought
prompt = "A bat and a ball cost $1.10. The bat costs $1.00 more than the ball. How much is the ball?"
# Model might guess: $0.10 (wrong!)
# With Chain-of-Thought
prompt = """Let's solve this step by step:
1. Total cost = $1.10
2. Bat = Ball + $1.00
3. Ball + (Ball + $1.00) = $1.10
4. 2 × Ball = $0.10
5. Ball = $0.05
The ball costs $0.05."""
When Thinking Needs Action
Plain-English definition: ReAct Loops (Reasoning + Acting) combine the model’s internal reasoning with external actions like searching the web, querying a database, or running code. The model thinks, acts, observes the result, then thinks again.
How it works: The system follows a cycle: Thought → Action → Observation → Thought. It generates a reasoning step, decides what action to take, executes it, receives feedback, and incorporates that feedback into its next reasoning step.
Analogy: It’s like a detective who doesn’t just think about the case in their armchair. They form a hypothesis, go interview a witness, come back with new information, refine their theory, then check another lead.
# Simplified ReAct loop
action_history = []
thought = "I need to find the current temperature in Tokyo."
while not answer_found:
action = model.generate(f"Thought: {thought}\nAction: ")
if action == "search_weather":
result = weather_api.get_temperature("Tokyo") # 72°F
observation = f"Temperature in Tokyo: {result}°F"
elif action == "final_answer":
answer = result
answer_found = True
thought = model.generate(f"Observation: {observation}\nThought: ")
Gotcha: ReAct loops can get stuck in infinite cycles if the model keeps choosing actions without reaching a conclusion. You need a Decision-Making Boundary (we’ll cover that soon) to stop the loop.
The Architecture of Cognitive Loops
Plain-English definition: Cognitive Loops are the iterative reasoning cycles that combine CoT and ReAct into a unified thinking process. Each loop consists of reasoning, deciding, acting, and integrating feedback.
How it works: The system enters a loop. It reasons using CoT, considers what action to take (if any), executes that action, observes the result, and feeds the observation back into the next reasoning step. This continues until it reaches a final answer.
Analogy: Imagine you’re assembling IKEA furniture. You read the instructions (reason), realize you need a screwdriver (action), go get it (execute), see the screw fits (observation), then read the next step (reason again). Each loop gets you closer to a finished bookshelf.
cognitive_loop = {
"state": "reasoning",
"steps": [],
"max_iterations": 5
}
while cognitive_loop["state"] != "complete":
step = model.generate_reasoning(history)
cognitive_loop["steps"].append(step)
if step.requires_action:
result = execute_action(step.action)
integrate_observation(result)
if should_stop(cognitive_loop):
cognitive_loop["state"] = "complete"
Performance implication: Each loop costs money and time. A ReAct loop with 10 iterations might cost 10x more than a single-shot answer. Cognitive loops are powerful but expensive.
Breaking Down the Impossible
Plain-English definition: Task Decomposition is the process of splitting a large, complex problem into smaller, manageable subproblems that can be solved independently.
How it works: The model analyzes the main task, identifies dependencies, creates sub-goals, and solves each piece separately. This mirrors how humans tackle complex projects — you don’t build a house in one step; you pour the foundation, frame the walls, add the roof, etc.
Analogy: Writing a 100-page report feels impossible. Writing ten 10-page chapters? Much more manageable. Task decomposition is the art of finding those chapter boundaries.
complex_task = "Build a recommendation engine"
# Task Decomposition in action
subtasks = model.decompose(complex_task)
# Returns:
# 1. Collect user interaction data
# 2. Preprocess and clean the data
# 3. Choose a recommendation algorithm
# 4. Train the model
# 5. Evaluate performance
# 6. Deploy as API
for subtask in subtasks:
result = solve_with_cognitive_loop(subtask)
integrate_into_solution(result)
Non-obvious insight: Bad task decomposition can make problems harder. Decomposing a problem into highly interdependent subtasks creates more overhead than solving it directly. The decomposition strategy matters as much as the decomposition itself.
Knowing When to Stop
Plain-English definition: Decision-Making Boundaries are the rules or heuristics that determine when a cognitive loop should stop reasoning and produce a final answer.
How it works: These boundaries include maximum iteration limits, confidence thresholds (stop when the model’s confidence in its answer exceeds 90%), time limits, and token budgets. Without them, the system might reason forever or never commit to an answer.
Analogy: It’s the “two-minute rule” for AI reasoning. If you can’t reach a confident answer within the boundary, you accept uncertainty and move on. Perfectionism kills productivity, even for language models.
class DecisionBoundary:
def __init__(self, max_steps=10, confidence_threshold=0.8, max_tokens=1000):
self.max_steps = max_steps
self.confidence_threshold = confidence_threshold
self.max_tokens = max_tokens
def should_stop(self, model_state):
if model_state.steps >= self.max_steps:
return True # Maximum iterations reached
if model_state.confidence >= self.confidence_threshold:
return True # Confident enough
if model_state.tokens_used >= self.max_tokens:
return True # Budget exhausted
return False # Keep reasoning
Edge case: Setting boundaries too tight causes premature, wrong answers. Setting them too loose wastes resources. Finding the sweet spot requires experimentation with your specific use case.
How They All Connect
| Concept | What It Does | When to Use | Cost |
|---|---|---|---|
| Central Reasoner | Core text generation | Always present | Baseline |
| Chain-of-Thought | Show reasoning steps | Multi-step problems | Slightly higher |
| ReAct Loop | Combine reasoning + action | Tasks needing external info | Much higher |
| Cognitive Loop | Iterative reasoning cycle | Complex, multi-step tasks | Highest |
| Task Decomposition | Break problems into pieces | Very complex problems | Upfront cost |
| Decision Boundary | Stop reasoning at right time | All loop-based approaches | Free |
Key Takeaways
- Central Reasoner: The core model that generates all text — efficient but limited on complex tasks
- Chain-of-Thought: Prompting technique that forces step-by-step reasoning, improving accuracy on multi-step problems
- ReAct Loops: Cycle of reasoning, action, and observation that enables tool use and self-correction
- Cognitive Loops: The unified framework that combines CoT, ReAct, and feedback integration
- Task Decomposition: Strategy to simplify complex problems by solving independent subproblems
- Decision-Making Boundaries: Essential guardrails that prevent infinite loops and wasted compute
The magic isn’t in any single technique. It’s in how they compose. Chain-of-Thought makes the reasoning visible. ReAct adds action. Cognitive loops add iteration. Task decomposition adds structure. And boundaries add discipline. Together, they transform a glorified autocomplete into something that looks — and often acts — surprisingly like thought.

Comments